# 笔记
[[UniDic]] 官网的[用語集](https://clrd.ninjal.ac.jp/unidic/glossary.html)的备份。最关键的就是关于[[短单位]]的论述和[[UniDicの品詞体系]]的介绍。
# 原文:「UniDic」国語研短単位自動解析用辞書 用語集
- [『日本語』形態素解析と短単位自動解析](https://clrd.ninjal.ac.jp/unidic/#morphological_analysis)
- [短単位](https://clrd.ninjal.ac.jp/unidic/#suw)
- [階層的な見出し構造](https://clrd.ninjal.ac.jp/unidic/#kaisouteki)
- [可能性に基づく品詞体系](https://clrd.ninjal.ac.jp/unidic/#kanousei)
- [語彙表IDと語彙素ID](https://clrd.ninjal.ac.jp/unidic/#lid_and_lemma_id)
## 『日本語』形態素解析と、短単位自動解析
「形態素解析」 は "Morphological Analysis” の和訳ですが、 一般に、 『日本語』形態素解析 と言ったとき、それはもともとの Morphological Analysis と同じ解析処理ではありません。
Morphological Analysis は、英語のような語形変化のある言語に対し以下のように、 与えられた「単語」の出現形を、それを構成する 形態素(morpheme) へと分解する処理を指します(くわしくは\[Jurafsky, 09\]、\[永田, 99\]、\[吉田, 84\]を参照して下さい)。
| loving | → | love | + | ing(進行形) |
| --- | --- | --- | --- | --- |
| happiest | → | happy | + | est(最上級) |
| girls | → | girl | + | s(複数) |
一方、日本語解析処理の文脈で「形態素解析」と言ったとき、基本的には以下の3つの処理を行うことを指します。
- ① 与えられた文字列(主に「文」)の分かち書き(Segmentation)
- ② 品詞タグ付け(Part Of Speech (POS) Tagging)
- ③ 活用推定(+原形推定)(Lemmatization)
両者の大きな違いは、もともとの Morphological Analysis が単語をスタートとする解析処理であるのに対し、 日本語の形態素解析が①のように、分かち書き処理を含んでいることです.
これには次のような理由があります。
英語は、文中の空白で区切られた単位が単語である、という暗黙の了解がある。 つまり「分かち書きされている言語」です。 対する日本語は、文が単語に「分かち書きされていない言語」です。 そのため、日本語に欧米で開発された単語ベースの自然言語処理の手法を適用するためには、まず分かち書きの自動化がどうしても必要でした。
日本語を計算機を使って自動で分かち書きする際、品詞や活用は非常に強力な情報となります。 しかし品詞や活用を定めるためには、そもそもそれらの付与される対象が分かち書きによって切り出されていないといけません。 そこで、品詞や活用までを記憶した電子化辞書が整備され、それを使って①~③の処理を同時に行う自動分かち書きの手法が提案され\[長尾+, 78\]、 その処理の中に Morphological Analysis に含まれる③の処理を含んだことから、 この解析を日本語では「形態素解析」と呼んでいるわけです\[長尾+, 78\]\[首藤, 80\]。 また③の処理を行うためには、①②との同時処理が必要である、という見方もできます\[吉田, 84\]。
また「形態素」解析と呼んでいますが、日本語の形態素解析は一般に、 入力文字列を「形態素」ではなく「単語」に分割した上で、その品詞や活用などの文法機能を同定する処理と見なされています。 (つまり、日本語形態素解析はMorphological Analysisのように形態素単位へ分割する処理ではないのですが、「形態素」解析という呼び方が定着してしまっていることもあり、しばしば混乱を招いています)
ただし、分かち書きをしない日本語において「何を『単語』と見なすか?」は自明でなく、 日本語母語話者の間でも、皆が納得するような明確な「単語」の定義はありません。 そのため実際の解析における分割の単位は、「解析用辞書にどのような基準で表層形を登録したか?」に依存して決まります。
UniDicの場合、この「基準」として以下で述べる「 [短単位](https://clrd.ninjal.ac.jp/unidic/#suw) 」を設定しているため、 解析結果は、入力文字列を短単位へと分割したものとなります。
そのためUniDicを使った形態素自動解析を「短単位(自動)解析」とも呼びます。
### 補足: 工学的目的としてのUniDic
\[吉田, 84\]によると、形態素解析の工学的目的には、大きく2つの立場があります。
1つ目は、形態素解析を後段の構文解析・意味解析へ進むための準備段階と捉え、機械翻訳・質問応答・情報検索など、より下流の解析処理を目指していく立場です。
2つ目は、この形態素解析の段階での結果を最終的なものとして使用する立場で、 短単位のアノテーション補助を目的に作られているUniDicにとっては、この2つ目の立場が当てはまります。
### 参考文献
- 永田 昌明: 「形態素解析、構文解析」, 自然言語処理―基礎と応用, 電子情報通信学会, pp.2-45 (1999).
- Daniel Jurafsky: Words and Transducers, SPEECH and LANGUAGE PROCESSING: An Introduction to Natural Language Processing,Computational Linguistics, and Speech Recognition, Internatinal Edition, Chapter3 (2009).
- 長尾 真, 辻井 潤一、山上明、建部周二: 「国語辞書の記憶と日本語文の自動分割」, 情報処理, vol.19, No.6、pp.514-521 (1978).
- 本文中では「単語単位への分割と品詞認定」と書かれているが、英文アブストラクトには「Morphological analysis of Japanese sentences」と記載されている。
- 首藤 公昭: 「日本語の形態素解析について」, 計算言語学, vol.21, No.3, pp.1-6 (1980).
- 本文中で「欧米語における語の屈折を取扱う段階の類似性から」「(広義の)形態素解析と呼ぶこともできよう。」と記載されている。
- 吉田将: 「形態素解析」, 日本語情報処理:第4章, 電子情報通信学会, pp.86-113 (1984).
- 言語処理学会 編: 言語処理学事典, 共立出版 (2009).
## 短単位
### 国語研の語彙調査と、斉一(せいいつ)な言語単位
国語研はこれまで何度もの日本語の [語彙調査](http://www.ninjal.ac.jp/info/aboutus/photo/4/chapter_04.html) を実施してきました。 語彙調査というのは簡単に言うと、我々が日常的に使う「語」がどのくらいの数で、それぞれの「語」がどのくらいの頻度で使われているかを調査するものです。 語彙調査の詳細は、\[山崎, 13\]を参照してください。
語彙調査を実施するに当たっては、まず「『語』とは何か?」ということが重要になります。 しかし、分かち書きをしない日本語において「何を『単語』と見なすか?」は自明でなく、日本語母語話者の間でも、皆が納得するような明確な「単語」の定義はありません。 例えば、「国立国語研究所」という文字列を全体で1語と考える人もいれば、 「国立\国語\研究\所」のように細かく区切ったそれぞれを1語だと考える人もいます。 また1人の人間であっても「青空」は1語だとみなすけれど、「梅雨\空」になると2語だとみなす というように、似たような文字列を異なる方法で分割する場合もありえますし、必ず毎回同じ分割をするとも限りません。
コーパス中の分割に不統一があると、その用例検索に問題が生じます。例えば、1つのコーパス中で「研究所」が「\研究所\」と「\研究\所\」の2通りの方法で分割されていたとすると、「研究所」の全用例を集めるためには、「研究所」のほかに「研究」+「所」も検索しなくてはいけません。また、「研究所」と似たような文字列の構成を持つ「資料館」や「博物館」を検索するときには、これらがどういった分割でコーパスに格納されているかを毎回すべて確認する必要があります。
また、分析においても斉一性の確保は重要です。 \[大野, 56\]では、古典文学8作品の品詞比率を索引を基に調査し、 万葉集において、動詞の比率が8作品中でもっとも低い、という結論を出しています。 しかし\[宮島, 69\]ではそれを、\[大野, 56\]で使用された万葉集の索引がほかの索引と異なり、複合動詞の多くを分割していることによる結果ではないかと指摘し、分割基準をほかの作品とそろえると、万葉集の動詞比率は枕草子などの随筆作品に近くなると述べています。
この問題を受けて、\[中野, 98\]では、言語の計量的研究における「調査単位」が備えているべき条件として以下を挙げています。
<table><tbody><tr><td rowspan="2">{</td><td>1)その単位は、対象となる言語表現の何について調べるためのものであるかが、誰にでもわかり、誰でもが試みることができ、再試すれば同じ結果を得ることができるものであること。</td><td rowspan="2">}</td></tr><tr><td>2)ある言語現象に対して、あいまいさや矛盾がなく、一義的にその単位を切り取ることができること。切り取られた単位は等質であること。</td></tr></tbody></table>
そこで国語研での語彙調査では、調査単位(単位語)の設定に当たって、 「調査目的に対して最もふさわしい単位を設計する」 という方針の下、
| { | 「これこれこういうものを『~単位』とする」という規定をするだけで、 その「~単位」が言語学的にどういうものなのか、 単語なのか、単語でないとするなら、どこが単語と違うのか といった問題にはまったく触れない | } |
| --- | --- | --- |
という「操作主義的な立場」を一貫してきました。
この操作主義的な立場を守り、現代日本語書き言葉均衡コーパス(BCCWJ)やUniDicでも、語彙調査の時と同じく、 \[中野, 98\]の条件をみたすよう、規程集によって厳格な言語単位の認定手続きが与えられています。
### 現代日本語書き言葉均衡コーパス(BCCWJ)とUniDicの言語単位
UniDicはもともと、現代日本語書き言葉均衡コーパス(BCCWJ)の形態論情報アノテーション用に開発された辞書です。 [UniDicとは](https://clrd.ninjal.ac.jp/unidic/about_unidic) でも述べましたが、UniDicデータベースは、コーパスデータベースと密接に関係しているため、UniDicが 採用している見出しの登録方針もBCCWJの言語単位(単位語)の設計方針と一致しています。
BCCWJへ形態論情報を付与する際の言語単位は、語彙調査同様に、まず目的を設定した上でその目的に適した単位を設計しました。 この場合の目的とは、
「BCCWJを使って、どのような言語研究を行いたいか?」
ということで、 BCCWJでは次のような方針を掲げています。
| { | コーパスに基づく用例収集、各ジャンルの言語的特徴の解明に適した単位を設計する。 | } |
| --- | --- | --- |
コーパスの日本語研究への活用としてまず考えられるのは、コーパスから用例を集めることです。 そのためBCCWJを日本語研究で幅広く利用できるようにするには、
① 用例収集に適した単位を設計する必要がある。
またBCCWJは、新聞・雑誌・書籍といった複数の媒体を対象としたコーパスであり、 内容も政治・経済・自然科学・文芸等と多岐にわたっています。そのため、
② 媒体別・ジャンル別の言語的な特徴を明らかにしていくことが重要な研究テーマになると考えられ、 そのような分析に適した単位を設計することが必要になる。
以上の①、②の必要に応じて、BCCWJが採用したのが以下の2つの単位です。
- ①' 用例収集を目的とした短単位
- ②' 言語的特徴の解明を目的とした長単位
短単位は、言語の形態論的側面に着目し、下で述べる最小単位を基に斉一性を重視して規定された言語単位(単位語)です。 1単位あたりの字数も短い(少ない)ため、短い検索クエリで目的の用例を広く多く集めることに向いています。 一方、長単位は、短単位では捉え難い複合語をカバーすることで、短単位よりも長い特定の語に着目した用例検索に向いています。 また文節を自立部と付属部にわけることで認定するため、言語の構文的な機能に着目して規定された言語単位ともいえます。 UniDicはこのうち、短単位の辞書というわけです。
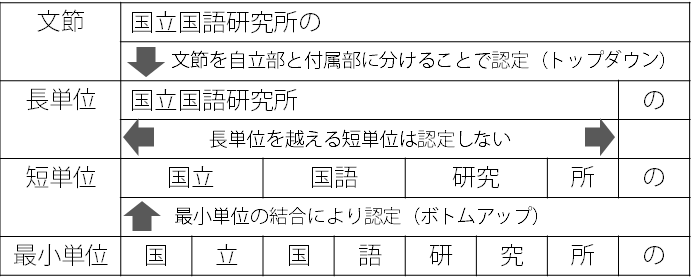
補足:短単位と長単位の二重アノテーションを初めて実施したのは『日本語話し言葉コーパス(CSJ)』ですが、そのときは、短単位は「斉一性を重視した形態重視の単位」、長単位は「短単位では捉え難い複合語をカバーするための単位」と考えていました。 長単位が「構文的な機能に着目して規定された言語単位」という意味合いを持つようになったのは、BCCWJの規定からです。
## 短単位の概要
短単位は、BCCWJからの用例収集を目的として、言語の形態論的側面に着目して 規定された単位です。 「形態論的側面に着目して」ということは、単語の内部構造を扱う領域の単位であり、長単位は反対に統語論、単語を組み合わせて文を作る領域の単位といえます。
短単位の認定に当たっては、 まず現代語において意味を持つ最小の単位(以下で説明する、 [最小単位](https://clrd.ninjal.ac.jp/unidic/#minimum_unit) )を規定します。 その上で、 最小単位を短単位の認定規定に基づいて結合させる、または結合させないことにより、 短単位を認定します。
そのため、短単位の認定規程は、最小単位と短単位、2つの認定規定から成ります。
### 補足:短単位の認定
UniDicデータベースへの辞書見出し追加は、 「コーパスの短単位情報アノテーションを行っていくの際に出現した短単位を、随時追加していく」が基本方針です。 そのため、アノテーション中のコーパスから、短単位を切り出して、UniDicデータベースに 照合するプロセスを踏むのですが、 この「切り出し」が上で言う「短単位の(境界)認定」です。 また切り出してきた短単位の品詞・活用を定めるのが「品詞認定」。 語彙素読み・語彙素を定めるのが「語彙素認定」。 発音形出現形を定めるのが「発音形認定」です。
### 最小単位とその認定規定
最小単位は、現代語において意味を持つ最小の単位で、言語学で言う形態素に概ね相当しますが、 「活用語の活用語尾を独立した単位としない」などの違いがあります。 また、漢字は基本1字で1最小単位となります。
最小単位は、和語、漢語、外来語、記号、人名、地名の種類ごとに次の表のように規定されています。
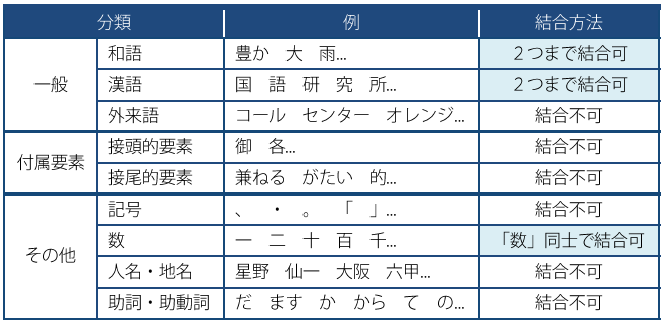
(「結合不可」・・・1最小単位=1短単位)
和語・漢語・外来語の語種の判定は、 原則として『新潮現代国語辞典』第2版(新潮社)により、 『新潮現代国語辞典』第2版の見出しにない語は、『日本国語大辞典』第2版(小学館)を主たる資料として語種判定を行います。 また『新潮現代国語辞典』第2版の語種判定に従い難いと判断した場合は、『日本国語大辞典』第2版等を参照して、独自に語種を判定しています。
注意すべき点として、最小単位は短単位の認定を行うために規定するものであり、短単位の認定のために必要な「概念」としてしか存在していません。
### 短単位の認定規定
短単位の認定規定は、上の最小単位の表の分類ごとに適用すべき規定が定められています。 その規定に基づいて最小単位を結合させる、もしくは結合させないことで、短単位を認定します。 結合既定の詳細は [『形態論情報規定集(下)』](http://doi.org/10.15084/00002856) を参照して下さい。
形態論情報規程集は、100ページを超える分厚さですが、実はほとんどが例外規定で、 基本となるルールは、以下の2つを原則とする単純なものです。
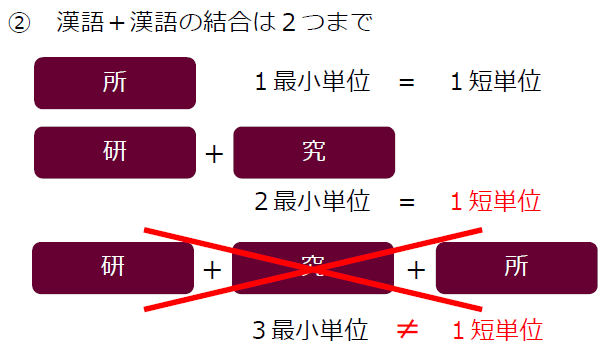
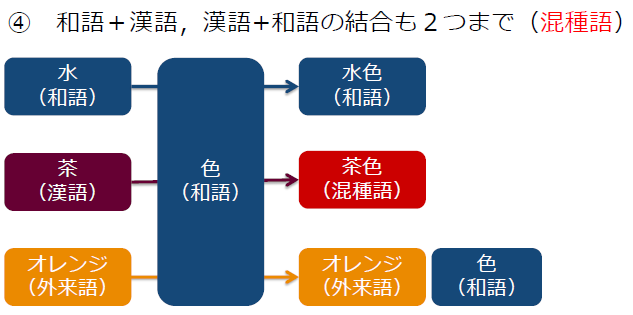
- 和語・漢語は、2最小単位の1次結合体を1短単位とする。 |母=親| |食べ=歩く| |言=語|資=源| |研=究|所| |本=箱|作り|
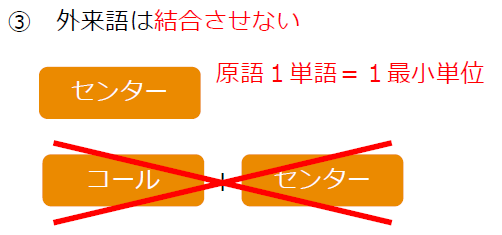
- 外来語は、1最小単位を1短単位とする。 |コール|センター| |オレンジ|色|
もう少し分かりやすく図を使って表すと、次のようになります。
### 補足:短単位の長所
短単位の特徴としては、 次の2点が挙げられます。
長所1: 基準が分かりやすく、ゆれが少ない。
これは、短単位の基礎となる最小単位の認定の時点で、基準に、人によって捉え方がゆれるような要素を持ち込んでいないことによります。 また、基準が分かりやすく、ゆれが少ないという短単位の長所は、作業効率の向上につながるだけでなく、 コーパスの使いやすさにもつながります。基準が分かりやすければ、利用者が語を検索する際、どのように検索条件を指定すればよいか迷うことが少なくなるためです。 また、ゆれの少なさ、つまりデータの精度の高さは、それを使った研究成果の確かさにもつながります。
長所2: 取り出した単位が文脈から離れすぎない。
上で短単位はゆれが少ない単位であると述べましたが、実は最もゆれが少ない単位は、短単位ではなく、その基礎となっている最小単位です。 それにもかかわらず、最小単位を言語単位として採用しなかったのは、最小単位は文脈から離れすぎ、 日本語の研究に使いにくいからです。 例えば、短単位「気持ち」は「気」と「持ち」の二つの最小単位に分割することができます。 もしこのような最小単位でコーパスが解析されていると、動詞「持つ」を検索した際に、 「荷物を持つ」などの「持つ」といっしょに、「気持ち」の「持ち」も検索結果として得られてしまうことになります。 ですが、動詞「持つ」の分析を行う際に、「気持ち」の「持ち」まで検索結果に含まれるのは望ましくありません。 それは、 実際の文脈の中では、動詞「持つ」として機能していないからです。 したがって、コーパスから用例を収集し、分析することを考えた場合、 正確に単位認定ができるとしても、最小単位のような単位では問題が多いということになるのです。
以上のように考えた場合、短単位は、
- 基準の分かりやすさ
- ゆれの少なさ
という条件を満たしつつ、 用例を収集して分析を行うという利用目的にもかなう単位と言えるのです。
参考文献
- 山崎 誠: 「語彙調査の系譜とコーパス」, 講座日本語コーパス, 1巻 コーパス入門, pp.134-158, 朝倉書店 (2013).
- 昭和の語彙調査データ: [https://pj.ninjal.ac.jp/corpus\_center/archive.html](https://pj.ninjal.ac.jp/corpus_center/archive.html)
- 大野 晋: 「基本語彙に関する二三の研究-日本古典文学作品に於ける」, 国語学, Vol.24, pp.34-36 (1956).
- 宮島 達夫: 「総索引への注文」, 国語学, Vol.76, pp.110-120 (1969).
- 中野 洋:「言語の統計」, 岩波講座 言語の科学9: 言語情報処理, pp.149-199, 岩波書店 (1998).
- [伝 康晴, 小木曽 智信, 小椋 秀樹, 山田 篤, 峯松 信明, 内元 清貴, 小磯 花絵: 「コーパス日本語学のための言語資源:形態素解析用電子化辞書の開発とその応用」, 日本語科学, Vol.22, pp.101-123 (2007).](https://doi.org/10.15084/00002185)
- 小椋 秀樹, 小磯 花絵, 冨士池 優美, 宮内 佐夜香, 小西 光, 原 裕: 「『現代日本語書き言葉均衡コーパス』形態論情報規程集 第4版 (上)」(LR-CCG-10-05-01) [http://doi.org/10.15084/00002855](http://doi.org/10.15084/00002855)
- 小椋 秀樹, 小磯 花絵, 冨士池 優美, 宮内 佐夜香, 小西 光, 原 裕: 「『現代日本語書き言葉均衡コーパス』形態論情報規程集 第4版 (下)」(LR-CCG-10-05-02) [http://doi.org/10.15084/00002856](http://doi.org/10.15084/00002856)
## 階層的な見出し構造
[上](https://clrd.ninjal.ac.jp/unidic/#suw) では、短単位が用例検索のための単位だということを説明しました。 しかし実は、UniDicにはさらに、用例検索に向けた設計思想が施されています。 それが、階層的な見出し構造です。
例えば、簡単な例として、コーパスから「大きい」という短単位の用例を集めたいとします。 単純な文字列検索ですと、例えばですが、もしコーパス中に「巨大きいちご」という文字列があったとしたら、 その文字列まで用例として上がってきてしまいます。 しかし、短単位に分割済みのコーパスならば、「巨大|きいちご」と分割してあるので、 この用例まで列挙してしまうことはありません。
では、「大きい」の連用形である「大きく」や、仮定形の「大きけれ」はどうでしょうか? もし、集めたい対象が活用変化を含まないのならば、単に「大きい」という表層形(書字形出現形)を 集めればいいかもしれません。 しかし、もし「大きい」という短単位を活用の変化も含めてすべて列挙したいとするなら、どうすればいいでしょうか?
この問題に対応するため、UniDic中の書字形出現形には、対応する書字形基本形という項目が設定されており、 活用変化する短単位には、その書字形出現形が活用変化する前の基本形(終止形)、活用しない短単位には当該の書字形出現形がそのまま登録されています。 「大きい」「大きく」「大きけれ」の場合、いずれの書字形基本形も「大きい」です。 なので、書字形基本形が「大きい」の短単位を集めれば、活用変化を含めてすべての「大きい」の用例を集められます。
しかし、もしコーパス中に「大きい」が「おおきい」と平仮名表記されていたらどうでしょう? 「大きい」「大きく」「大きけれ」の書字形基本形は「大きい」ですが、「おおきい」「おおきく」「おおきけれ」の書字形基本形は「おおきい」です。 なので、書字形基本形で「大きい」の用例を集めても、「おおきい」の用例は集められません。
そこで、「大きい」や「おおきい」のような異なる表記を束ねる階層として、UniDicには「語形」があります。
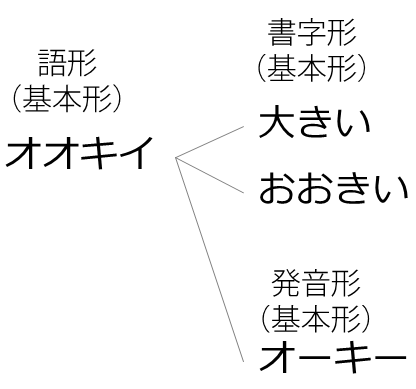
語形にも、書字形と同じく出現形と基本形があり、それぞれ書字形の出現形と基本形を束ねる形になります。
(実際のUniDicデータベース内では基本形をベースに短単位を管理しており、 活用変化してできる短単位には、活用変化表で派生対応しています。 詳しくは\[伝+, 07\]を参照して下さい)
また、語形は、カタカナを使って表記されます。 そのため、語形だけでは「回」と「下位」と「貝」を等しく扱ってしまいます。 これは書字形レベルでも同じで、平仮名で書かれたクエリ「かい」だけでは同音異義の「回」「下位」「貝」をすべて列挙してしまいます。 そのため、次に説明する「語彙素」を同時に指定して階層構造を利用した検索を行う必要があります。
ちなみに、UniDicでは、書字形の発音形(発音形出現形、発音形基本形)も書字形と並べて語形の直下にぶら下がる要素とすることで 同一語形下の書字形すべての発音を表すことにしています。
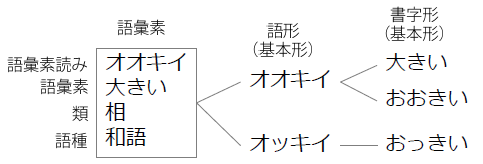
語形は「大きい」「おおきい」のような表記の違いをまとめる階層です。 そのため、「大きい」のくだけた表現である「おっきい」は発音が異なりますし、 「大きい」「おおきい」とは別の語形「オッキイ」とみなします。 また、口語・文語のような活用型の違いも別の語形とみなします。
これら異語形をまとめ上げる最上位の階層が「語彙素」です。 実際には、「語彙素読み」「語彙素(+語彙素細分類)」「語彙素類」の3つ組み情報ですが、 ここではまとめて「語彙素」と呼ぶことにします。
語彙素は語形の違いによらず、もともと同一と見なせる語形を1つにまとめ上げる、 辞書で言う「見出し語」に相当する階層です。 語彙素: (オオキイ、大きい、相)によって、異なる語形(基本形、出現形)が1つにまとめ上げられるので、 語彙素だけ指定して検索すると、異なる語形も一度に用例検索することができます。
また、見出し語としての語彙素は\[中野, 98\]の言語研究における調査単位が備えるべき条件の3つ目、
| { | 3) 切り取られた単位に対して、その見出し語が決まること。ある単位と別の単位が同じ見出しを持つか否かが見分けられること。 | } |
| --- | --- | --- |
をみたすものとして作られています。 そのため、書字形から語彙素まで階層的に指定して検索することで、先に上げた、「回」「下位」「貝」が平仮名表記されている場合も区別して 検索することが可能となっています。
これが、階層的な見出し構造です。 ここでは概略しか述べていませんが、もっと詳しく知りたい人は\[伝+ 07\]を参考にしてください。
### 語源主義に基づく脱文脈化
- 我々のメンツに関わる問題だ
- 野球のメンツがそろわない
この2つの「メンツ」を見たとき、2つが同じ意味だと思う人はほとんどいないでしょう。 ですが、日本国語大辞典を引くと、この2つの「メンツ」は実は同じ見出し語「メン‐ツ 【面子】 」として登録されています。 ただし、
- 1)体面。面目。
- 2)マージャンを行なうのに必要な人。また、一般にある集まりの参加者。
といったふうに、見出し語の下で異なる語義として並べられています。 これは日本国語大辞典が派生的な意味を別語として扱わないで、語源主義によって見出し語を立項しているからです。
「我々のメンツにかかわる問題だ」の「メンツ」は「体面。面目。」の語義にあたり、 「野球のメンツがそろわない」の「メンツ」は「ある集まりの参加者。」の語義にあたります。
これに対し、UniDicデータベース内でも、この2つの「メンツ」の語彙素を同一のものとして、区別しません。 これが、語彙素が「辞書の見出し語相当のもの」といわれる理由の1つであり、 短単位の「語源主義に基づく脱文脈化」です。 「脱文脈化」とは、「文脈に即した意味までは扱わない」という意味で、長単位が文脈に依存するのに対し、短単位は文脈から離れて、辞書として独立した見出しを立てています。
参考文献
- 中野 洋:「言語の統計」, 岩波講座 言語の科学9: 言語情報処理, pp.149-199, 岩波書店 (1998).
- [伝 康晴, 小木曽 智信, 小椋 秀樹, 山田 篤, 峯松 信明, 内元 清貴, 小磯 花絵: 「コーパス日本語学のための言語資源:形態素解析用電子化辞書の開発とその応用」, 日本語科学, Vol.22, pp.101-123 (2007).](https://doi.org/10.15084/00002185)
## 可能性に基づく品詞体系
UniDicの品詞体系では、 可能性に基づく品詞体系 を採用しています。 これは、用法による品詞の区別は行わず、当該短単位がとり得る用法をすべて考慮した1つの品詞を付与することを目標とした品詞体系です。
例えば、「今度」という短単位は以下のように.文脈に応じて複数の品詞をとり得ますが、 これには「名詞-普通名詞-副詞可能」という複合的な品詞が付与されます。
- 今度(副詞)行きます。
- 今度(名詞)が最後だ。
この品詞体系の最大の特徴は、用法による品詞の区別を「あえて」行なわない点です。
可能性に基づく品詞体系は、IPA辞書でも採用されていますが、 上でも述べた通り、短単位は形態論的側面に着目した用例収集のための単位であり、
- ① 用例検索する際に、文脈に依存しない用例収集を可能にするため
- ② 人手のアノテーションの際の揺れを減らすため
UniDicでは、この複合的な品詞が以下のようにIPA辞書にくらべて多く設定されています。 (IPA辞書では、「副詞可能」くらいしかありません)
1. 名詞-普通名詞-サ変可能(e.g., 運動、アクセス)
2. 名詞-普通名詞-形状詞可能(e.g., 安全、健康、アクティブ)
3. 名詞-普通名詞-サ変形状詞可能(e.g., 安心、おしゃれ、オーバー)
4. 名詞-普通名詞-副詞可能(e.g., 今日、毎日、以上、今度)
5. 名詞-普通名詞-助数詞可能(e.g., 円、ドル、メートル、グラム、時間、箇月、条)
6. 動詞-非自立可能(e.g., する、くる、いく)
7. 形容詞-非自立可能(e.g., ない、欲しい、よい)
8. 接尾辞-名詞的-サ変可能(e.g., 化、ナイズ、分)
9. 接尾辞-名詞的-形状詞可能(e.g., 三昧、深)
10. 接尾辞-名詞的-サ変形状詞可能(e.g., unidic-mecab-2.1.2\_srcに0例)
11. 接尾辞-名詞的-副詞可能(e.g., 当り、中、後)
可能性に基づく品詞体系の多用には賛否両論あります。 例えば、UniDicでは非自立動詞と自立動詞の区別をなくし、 「する」「いく」「くる」のような非自立同士になり得る短単位に 「動詞-非自立可能」という品詞を付与しています。 そのため、UniDicの品詞体系では、 「学校にいく」の「いく」と、 「生きていく」の「いく」を区別しません。 このことはおそらく、解析結果に唯一の解を欲する自然言語処理の研究者やエンジニアにとって、 非常に不可解に感じられるかもしれません。 しかし例えば、「出勤するときはいつもコンビニに寄っていく」の「いく」が自立か非自立か、 と問われると、皆の意見が一致することは当然、1人の中でも識別を一貫していくことは困難でしょう。 そこであえて一方に倒してしまうのではなく、最終的な判断はその分野の研究者に任せ、 その判断自体を研究の対象としてもらうことをUniDicでは目指すことにしました。 UniDicにとって一番重要なのは、用例収集までであり、 現在の品詞体系は、用例の検索漏れを減らすべく、上記①と②に重きを置いた結果でもあり、 先に述べた脱文脈化の延長とも言えます。
また実は、長単位になると、構文等、文脈依存な検索のため、可能性に基づく品詞はありません。 そのため、コーパス中で当該の短単位を包含している長単位の品詞を参照することで、短単位の品詞の曖昧性は解消可能です。 また短単位解析の結果を自動的に長単位の列にまとめ上げる [Comainu](https://ja.osdn.net/projects/comainu/) \[小澤+, 2014\]というツールも存在します。
### UniDicの品詞体系
UniDicの品詞体系は(活用も含めて)学校文法におおむね基づき、形態素解析器MeCabのデフォルトの辞書である『IPA辞書(ipadic2.7.0)』や『岩波国語辞典』を参考に作られています。 また「形状詞」は形容動詞語幹相当の品詞です。 詳しくは、 [『形態論情報規定集(下)』](http://doi.org/10.15084/00002856) を参照してください。
### IPA辞書の品詞体系
情報処理振興事業協会(IPA)が定める品詞体系(THiMCO97)に基づき、 奈良先端科学技術大学院大学で拡張修正を行なったもの。
参考文献
- 伝 康晴, 小木曽 智信, 宇津呂 武仁, 山田 篤, 浅原 正幸, 松本 裕治: 「話し言葉研究に適した電子化辞書の設計」, 第2回「話し言葉の科学と工学」ワークショップ講演予稿集, pp.39-46 (2002).
- 小澤 俊介, 内元 清貴, 伝 康晴: 「長単位解析器の異なる品詞体系への適用」, 自然言語処理, Vol.21, No.2, pp.379-401 (2014).
- 小椋 秀樹, 小磯 花絵, 冨士池 優美, 宮内 佐夜香, 小西 光, 原 裕: 「『現代日本語書き言葉均衡コーパス』形態論情報規程集 第4版 (下)」(LR-CCG-10-05-02) [http://doi.org/10.15084/00002856](http://doi.org/10.15084/00002856)
## 語彙表IDと語彙素ID
解析用UniDicにver.2.2.0から、新たな [素性](http://taku910.github.io/mecab/learn.html#seed) (出力カラム)として、語彙表ID (lid)と語彙素ID (lemma\_id)が追加されました。これらはUniDic DBの中で各短単位を一意識別しているIDで、
- 語彙表IDは、UniDic DB中の各エントリ(短単位)を一意識別するためのID(主キー)
- 語彙素IDは、UniDic DB中の各語彙素(語彙素-語彙素細分類、語彙素読み、語彙素類)を一意識別するためのID
となっており、基本的には解析用UniDicのバージョンが上がっても 変化しない情報です。
これら2種類のIDはもちろん、てきとうにつけられたものでなく、 UniDicの階層的見出し構造を反映したものとなっています。
例えば、
- 語彙素-語彙素再分類: 百
- 語彙素読み:ヒャク
- 語彙素類:数
という“語彙素”の語彙素IDは「31678」です。
この10進数を2進数(0と1のbit列)に変換すると、

となります。
次にこの語彙素にぶら下がる書字形出現形「百」の発音形出現形 「ヒャク」「ビャク」「ヒャッ」「ビャッ」の語彙表IDを見ていきます。
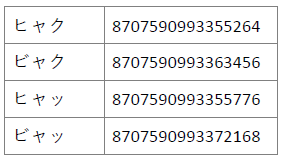
これらも語彙素IDと同じく2進数に変換してみます。

2進表記を上下で見比べてみると、頭の15桁(15bit)はどれも同じで、 しかもこれらの語彙素IDと同じ0と1の列となっています。
つまり、語彙表IDを2進数に変換したbit列中、先頭のこの部分は、 語彙素IDを表しているのです。
実は語彙素IDも語彙表IDも解析用UniDicの出力の上では 10進数で表示されているものの、 その本質は2進数に変換した長い0と1のbit列のほうにあります。
bit列の各部は次のような意味を持っています。
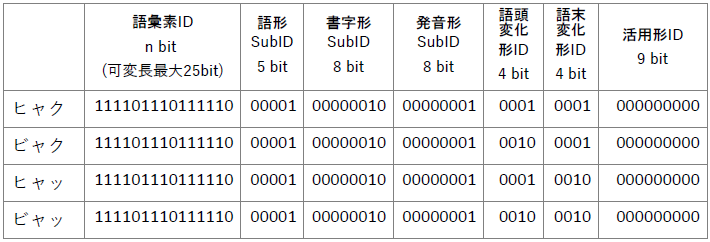
これをみると、4つの発音形出現形で異なっているのは 語頭変化形IDと語末変化形IDの部分だけです。
語頭が濁音化している「ビャク」と「ビャッ」では、 語頭変化形IDが「0010」ですが、 そうでない清音の「ヒャク」と「ヒャッ」は「0001」となっています。
また語末が促音になっている「ヒャッ」と「ビャッ」の 語末変化形IDは「0010」ですが、 そうでない「ヒャク」と「ビャク」は「0010」です。
「百」は名詞のため、語末変化の扱いが語末変化形で扱われていますが、 動詞や形容詞など活用のある短単位の場合、 最後の9bitの活用形IDで語末変化の区別が行われます。
少し専門的な話になりますが、これはすなわち次のことを意味しています。
- 当該短単位の語彙表IDを左に33bitシフトすることで、その語形基本形IDが得られる(当該短単位の語形基本形への変換・まとめ上げが可能)
- 当該短単位の語彙表IDを左に38bitシフトすることで、その語彙素IDが得られる(当該短単位の語彙素への変換・まとめ上げが可能)
語彙表IDの設定に関しては、 実際には上で説明した以上に細かな仕様があります。
詳しく知りたい方は下の参考文献で確認してみてください。
### IDの活用例
- [短単位数のカウント](https://clrd.ninjal.ac.jp/unidic/unidic/faq#count_suw)
- [語彙素IDと分類語彙表番号の対応データ](https://github.com/masayu-a/wlsp2unidic)
- [UniDic非コアデータ](https://teru-oka-1933.github.io/unidic_non_core/)
### 参考文献
- 小木曽 智信, 中村 壮範: 「『現代日本語書き言葉均衡コーパス』形態論 情報アノテーション支援システムの設計・実装・運用」, 自然言語処理, Vol.21, No.2, pp.301-332 (2014).
- 小木曽 智信, 中村 壮範: 「『現代日本語書き言葉均衡コーパス』形態論情報データベースの設計と実装 改訂版」(JC-U-10-01) [http://doi.org/10.15084/00002857](http://doi.org/10.15084/00002857)