稍微详细地介绍下日语自然语言处理会用到的工具 [[Mecab]] 的安装方法。[[2025]]年的话,优先推荐[[Sudachi]],因为这个安装起来实在太麻烦了。
<!-- more -->
# Mecab 安装指北
## 前言
如果只是少量分析的话,网上有现成的工具比如 [Web ちゃまめ](https://chamame.ninjal.ac.jp/),在线即可解析。
网上关于 Meacb 的安装教程不少,但仔细一看,往往写得过于随意。只有[日文分词器 Mecab 文档 我爱自然语言处理](https://www.52nlp.cn/%E6%97%A5%E6%96%87%E5%88%86%E8%AF%8D%E5%99%A8-mecab-%E6%96%87%E6%A1%A3#install)这篇翻译官方文档的文章有细细研读的价值。
此外,[Mecab 日语分词工具的简单使用 - FreeMdict Forum](https://forum.freemdict.com/t/topic/11762/8) 里的相关讨论也值得一读。
如果还有其他不错的教程,也欢迎补充。
在进入正题前,简单提一下影响「形态素解析」的 2 个关键要素:基于不同算法开发的形态素解析器,和形态素解析辞典。
解析器能看到不少,比如 [awesome-japanese-nlp-resources](https://github.com/taishi-i/awesome-japanese-nlp-resources)就能找到一大堆用各种编程语言开发、针对各种使用场景优化的解析器。
但形态素解析辞典就比较单一了,目前一般以 [ChaSen](https://ja.osdn.net/projects/chasen-legacy/)、[JUMAN](https://github.com/ku-nlp/jumanpp)、[Unidic 辞書](https://clrd.ninjal.ac.jp/unidic/) 三家为主,其中 ChaSen 最新版 2.4.5 更新时间 2012 年 6 月 25 日 ,JUMAN 最新版 1.02 更新时间 2017 年 1 月 12 日,只有 Unidic 辞書还能在最近 5 年内保持一年一更的频率。
目前来说,运用最广的开源形态素解析器就是 Meacb 了,下面就讲解下如何在 Windows 下安装使用。只要记住「形态素解析= 形态素解析器+形态素解析辞典」,安装其他形态素解析器也不会有太大的问题。
先提供一个备份的安装文件:
<https://www.123pan.com/s/iGz0Vv-svEVh.html>
## 通过安装包安装
先介绍一种最保险的方式,适合只需要默认解析格式的人。
首先到官网首页 [MeCab: Yet Another Part-of-Speech and Morphological Analyzer](https://taku910.github.io/mecab/#download)下载官方提供的安装包:[https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7WElGUGt6ejlpVXc](https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7WElGUGt6ejlpVXc)(备份安装包的对应路径: 形态素解析>形态素解析器>mecab)。
(网上能看到各种第三方库,其中一些第三方库自带了 Mecab 安装包,所以不用安装,但版本可能不是最新版的 0.996,所以更推荐像本篇文章一样,自己动手从头开始安装。)
安装时注意勾选`utf-8`编码,其他地方一直下一步即可。
注:可以更改程序路径,但更改后可能要手动添加到环境变量。其实 Meacb 的本体程序占用空间不大,个人觉得没有必要改路径。(主要是如果出了问题,可能得老老实实重装一遍 2333)
到这里,其实就算是安装好了,接下来直接通过命令行调用即可。具体的命令行可以参考[日文分词器 Mecab 文档 我爱自然语言处理](https://www.52nlp.cn/%E6%97%A5%E6%96%87%E5%88%86%E8%AF%8D%E5%99%A8-mecab-%E6%96%87%E6%A1%A3#install)。
## 通过 mecab-python3 安装
上面的方法调用起来不够灵活,无法满足需要处理大量自定义了格式的数据的场合。而且官方也没有提供 macOS 的安装包,所以下面再介绍一种通过 Python 调用的方法。
先安装第三方库`mecab-python3`:
```bash
pip install mecab-python3
```
然后用下面的指令安装并切换到 unidic-lite 词库。
```bash
pip install unidic-lite
pip install --no-binary :all: mecab-python3
```
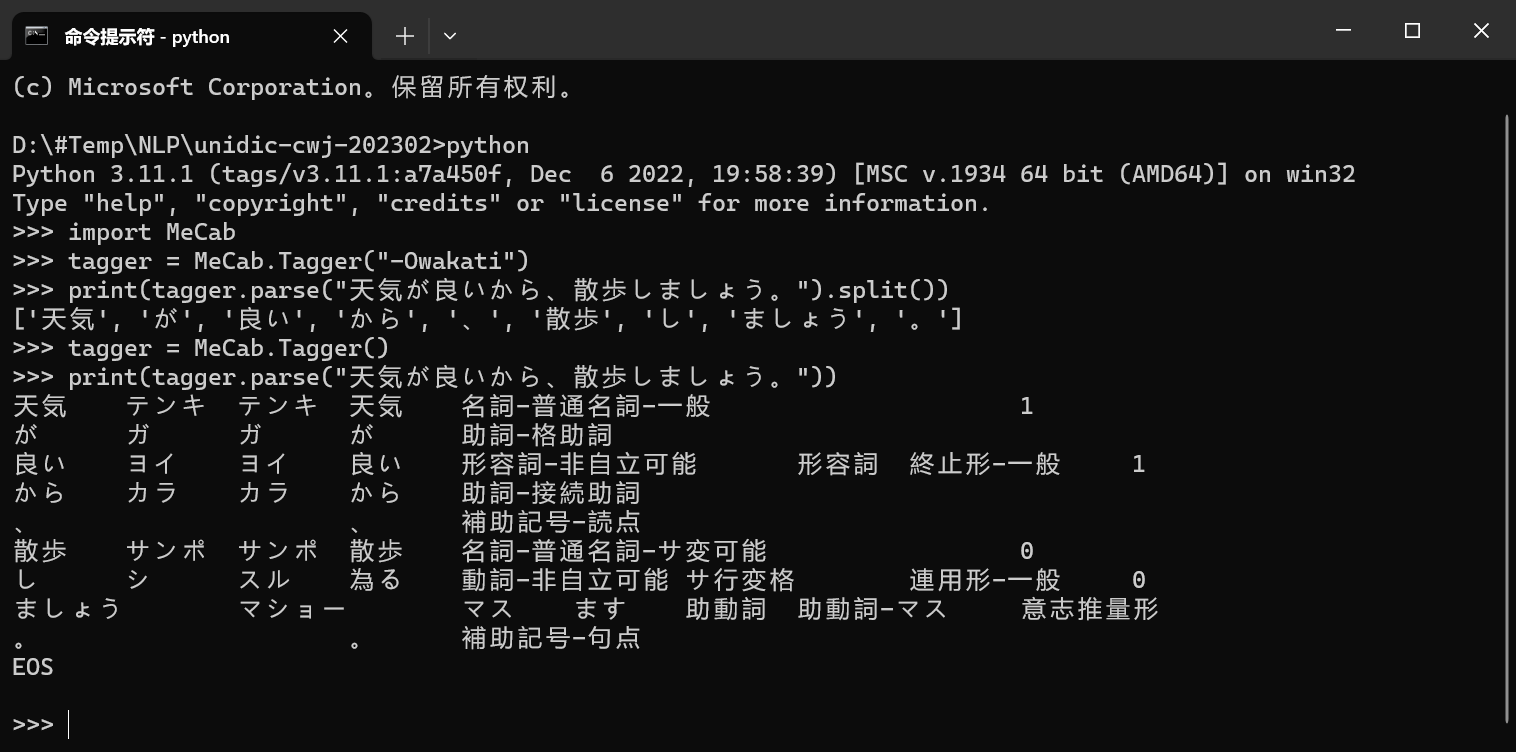
然后运行如下代码进行下测试,没有报错的话,就算是安装完成了。
```python
import MeCab
tagger = MeCab.Tagger("-Owakati")
print(tagger.parse("天気が良いから、散歩しましょう。").split())
tagger = MeCab.Tagger()
print(tagger.parse("天気が良いから、散歩しましょう。"))
```
## 可能会遇到的问题
Mecab 是基于C++开发的工具,网上能找到很多工具来调用。但经常会在配置环境这一步遇到一些意想不到的问题,这里记录一些反馈 :
以下来自 [amob](https://forum.freemdict.com/u/amob/summary)的反馈
> 首先,pip install一些基于C++的python库,要运行visual studio自带的命令行’Native(or Cross) Tools Command Prompt’,而不是系统默认的cmd。
> 也忘了之前看哪个坑人的mecab教程,因为mecab用命令行默认编码文字会无法显示,在注册表添加了autorun项设置了默认UTF-8,这也会影响Visual Studio环境的正常运行。。。
> 然后还是报错’Microsoft Visual C++ 14.0 is required’,才知道只要运行一句: `pip install --upgrade setuptools`
> 大功告成
> 参考网页:
> [visual studio:x64 Native Tools Command Prompt for VS 2019初始化失败_script “vsdevcmd\ext\active” could not be found.-CSDN博客](https://blog.csdn.net/qq1090504117/article/details/127681896)
> [python pip on Windows - command ‘cl.exe’ failed - Stack Overflow](https://stackoverflow.com/questions/41724445/python-pip-on-windows-command-cl-exe-failed)
> [‘Microsoft Visual C++ 14.0 is required’ in Windows 10 - Microsoft Community](https://answers.microsoft.com/en-us/windows/forum/all/microsoft-visual-c-140-is-required-in-windows-10/f0445e6b-d461-4e40-b44f-962622628de7)
## 自定义词库
通过安装包安装的 Meacb 自带的词库是 ipadic,这个词库的最后一次更新是在 2003 年 5 月。
通过 mecab-python3 安装的 unidic-lite,按照其 README 文档的说法,是 2013 年的版本 2.1.2:
> At the moment it uses Unidic 2.1.2, from 2013, which is the most recent release of UniDic that's small enough to be distributed via PyPI.
如果对解析精度有要求,更推荐安装日本国立国语研究所维护的 [Unidic 辞書](https://clrd.ninjal.ac.jp/unidic/)。
如果没有特殊需求,下载「現代書き言葉 UniDic」的最新版即可 <https://clrd.ninjal.ac.jp/unidic_archive/2302/unidic-cwj-202302.zip>(注: 2023 年 3 月 24 号更新,于 2024 年 2 月 23 日确认为最新版)(备份路径: 形态素解析> 形态素解析辞典> UniDic)
解压文件时,注意文件夹名,最好是 `unidic-cwj-3.1.1`(如果不是这么命名,请修改后续代码的`dic_path`)。

然后测试如下代码即可。
```python
import os
import MeCab
# 下面路径请和实际的安装路径保持一致,为了和截图保持统一,修改了文件夹的名字
dic_path = "D:\00temp\unidic-cwj-3.1.1"
tagger = MeCab.Tagger(
'-r nul -d {} -Ochasen'.format(dic_path).replace('\\', '/'))
text = "天気が良いから、散歩しましょう。"
print(type(tagger.parse(text)))
print(tagger.parse(text).split("\n"))
print(tagger.parse(text))
```
### mecab-ipadic-NEologd
mecab-ipadic-NEologd : Neologism dictionary for MeCab
项目地址: <https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md>
许可证:[Apache License, Version 2.0](https://github.com/neologd/mecab-ipadic-neologd/blob/master/COPYING)
项目名中的「Neologism」就是「新词」的意思,所以这个形态素解析辞典对于新词有较好的解析效果。不过需要自己编译源码,我没有折腾过,等大佬们出一个教程啦。
## 参考
[Mecab 日语分词工具的简单使用 - FreeMdict Forum](https://forum.freemdict.com/t/topic/11762/8) :提供了非常详细的说明和示例代码。
## 其他形态素解析器
前面提到了 [awesome-japanese-nlp-resources](https://github.com/taishi-i/awesome-japanese-nlp-resources)可以找到非常多的形态素解析器,除了根据具体的使用场景外,不妨也看看[MeCab の開発経緯](https://taku910.github.io/mecab/feature.html)里,对其他形态素解析器的评价:
> Juman 以前の商用的に配布されていた形態素解析器は, 辞書や品詞体系 連接規則はほぼ固定されており, ユーザ自身自由に定義できなかった. Juman は これらの定義すべて外部に出し自由な定義が可能になった.
> 辞書は比較的入手しやすいが, 連接コストや単語生起コストの定義は 人手によって行わざるをえなかった. 解析ミスを発見するたびに副作用が無い範 囲で連接コストを修正する必要があり, 開発コストが大きい.
> また, Juman は日本語の形態素解析として開発されていたので, 未知語処理が日本語に特化されており, 未知語処理の定義を 自分で与えることはできない. また, 品詞は 2 階層までに固定されており, 品詞体系には一種の制限がある.
> ChaSen の貢献の 1 つは, 統計処理 (HMM) によって連接コストや単語生起コストを 推定するようになった点にある. この処理のおかげで, 解析ミスを 蓄積するだけで自動的にコスト値を推定できるようになった. さらに, 品詞階層も無制限になり, 品詞体系を含めて(本当の意味で) 自由に定義できるようになった.
> しかし, 複雑な品詞体系にすればするほど, データスパースネスの問題が 発生する. HMM を使う場合, HMM の内部状態(Hidden Class)を 1 つに固定する 必要があるため, 各品詞から内部状態への「変換」が必要となる. 単純には 各品詞を 1 つの内部状態に割りあてればよいが, 活用まで含めて品詞を すべて展開すると, その数は 500 にも及び, 低頻度の品詞について 信頼度の高い推定量を得ることができない. 逆に, 頻度の高い「助詞」等の品詞は 語彙も含めて内部状態にしないと高い精度が得られない. 複雑な品詞体系にすればするほど, 内部状態の定義が困難になる. つまり, 現状の(複雑な)品詞体系を扱うには, HMM では力不足であり, それを補助するための人手コストが大きくなっている.
> また, ChaSen にはコスト値推定モジュールが付与されていない. NAIST の内部では利用できるらしいが, 上記の理由から設定すべき パラメータが多く, 使いこなすのが困難である.
> さらに, ChaSen も未知語処理もハードコーディングされており 自由に定義することはできない.
上面评价的关注点和形态素解析器的发展趋势基本一致:
1. 形态素解析器都在抛弃基于语法规则的思路,完全转向基于统计学的纯数学算法;
2. 放弃自定义形态素解析辞典,使用 UniDic 这样由权威机构构建维护的资源
3. 开始尝试同时支持多种语言的解析
下面列几个我个人稍微研究过的形态素解析器,:
[GiNZA - Japanese NLP Library](https://megagonlabs.github.io/ginza/):
开发语言:Python
许可证:MIT license
最后更新时间:2023-09-25
备注:由日本公司 recruit (日:リクルート)下属 AI 研究机构 Megagon Labs 于 2019 年开源的形态素解析工具。
[Kuromoji](https://github.com/atilika/kuromoji)
开发语言:Java
许可证:Apache-2.0 license
最后更新时间:5 年前
备注:从 MOJi Android 端 APK 解压后的结果来看,应该就是用的这个解析工具。另外,[[Elasticsearch]] 默认用的也是这个。