# 日语OCR软件推荐
如果只是偶尔用用的话,更推荐[白描](https://baimiao.uzero.cn/),支持 Android、iOS、Web 端。每天都有几次免费使用次数,用得少的话基本可以白嫖,而且也不贵,[30 的永久会员](https://apsgo.cn/qRqgZr),比起某扫描王一年将近 100 简直是白菜价(何况某扫描王识别效果也不是很好)。
至于那些套个 API 接口就敢上架的各种垃圾 APP,我建议各位不要浪费时间去下载尝试了,还不如看看[OCR 文字识别软件](https://www.yuque.com/docs/share/177c6f55-dfff-4fd5-8d71-7374c7128a5e)和
[秒杀年费 258 的同款 APP,微软、联想、Adobe、腾讯的良心产品太香了! ](https://mp.weixin.qq.com/s?__biz=MzA5NjEwNjE0OQ==&mid=2247504889&idx=1&sn=eac708f80285cf7eb630fb9c9b1c4fa2&chksm=90b7b033a7c03925574cd74b646e0e30a2787abe72928919a55577b1676ee586ca4504a823a0&scene=4))。
如果是想啃日语漫画的生肉,更推荐 [mokuro](https://github.com/kha-white/mokuro):将漫画转换一键转为适配了 Yomichan 的HTML,快速查词、添加到Anki
如果是有大量且高精度的使用需求,或者换个专业点的说法「译前处理」,更推荐 ABBYY——这个软件的对于日文竖排的识别效果可以说是真·降维打击一样的存在。
不过 ABBYY 使用起来确实比较难,网上针对日语的讲解更是少之又少,所以专门写了这篇文章,记录一个日语专业的学生使用 ABBYY 处理日语 PDF 技巧,希望对提问者有所帮助。
# 更改设置
安装好之后先找到 ABBYY FineReader PDF 15 这个软件,双击打开

在下面的界面下,找到`选项`,双击打开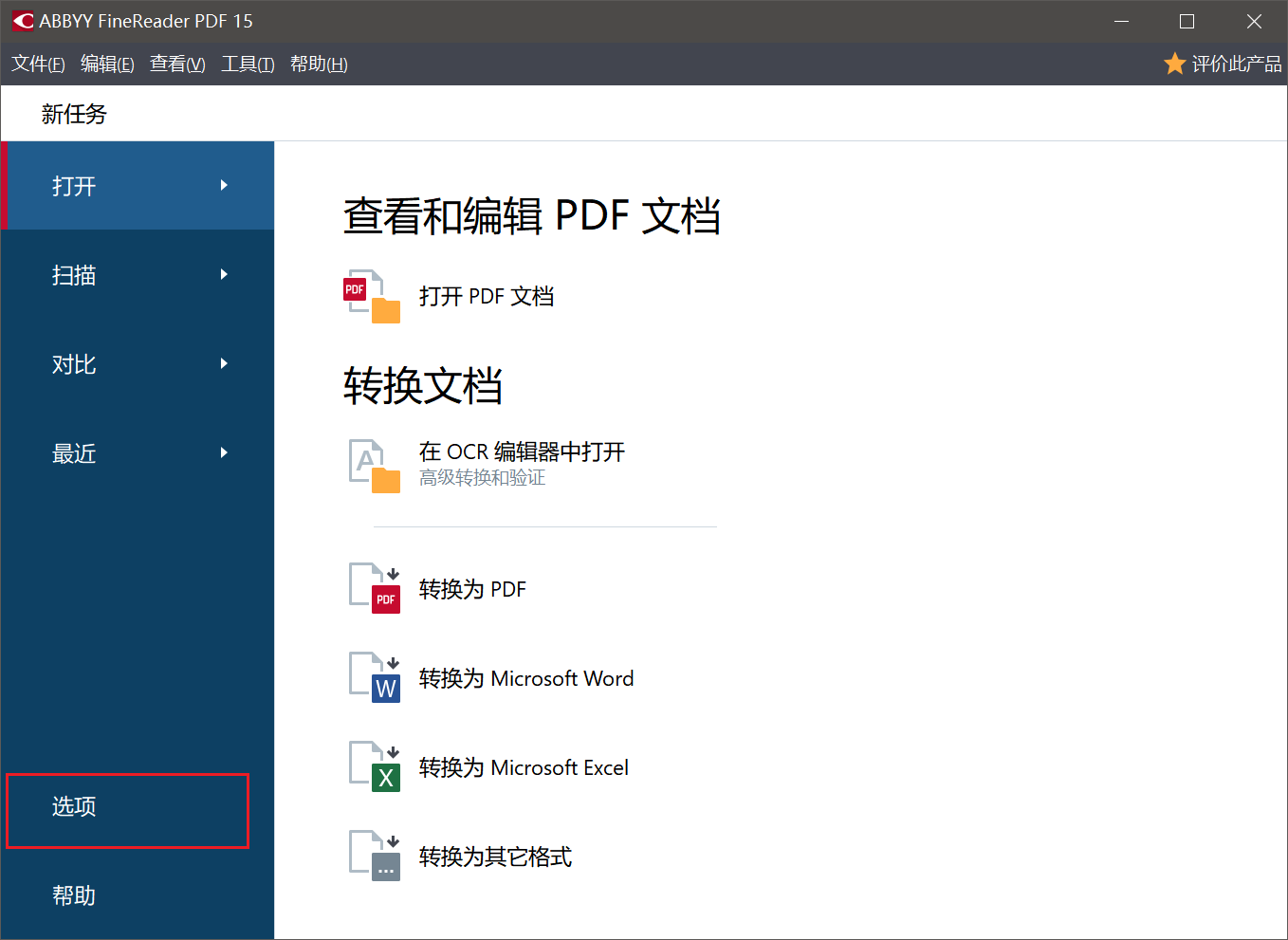
找到`图像处理`,点击一下

在下面这个界面,把红框框起来的地方都勾上吧(这样识别效果会好很多)
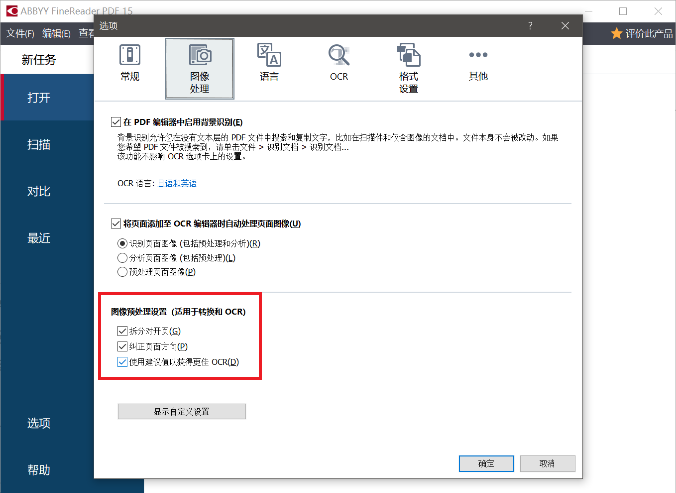
到此,已经完成了设置,接下来开始正式转换
# 转换为 Word
在电脑上装好 ABBYY 之后,右键点击一个 PDF 文件,是可以观察到下面这样的选项的,所以右键点击`转换为 Word 文档`
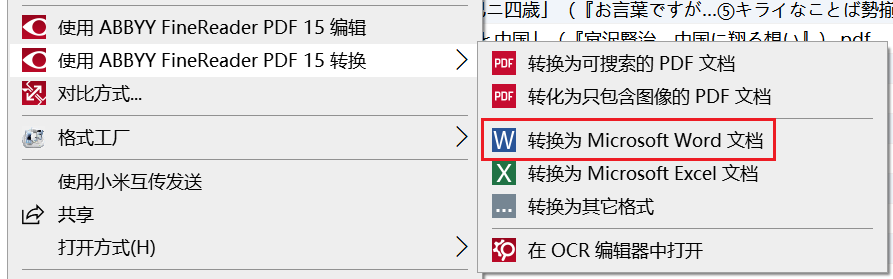
会弹出这么一个界面,注意一定要选择正确的语言,并且最好把`日语`放在第一个位置
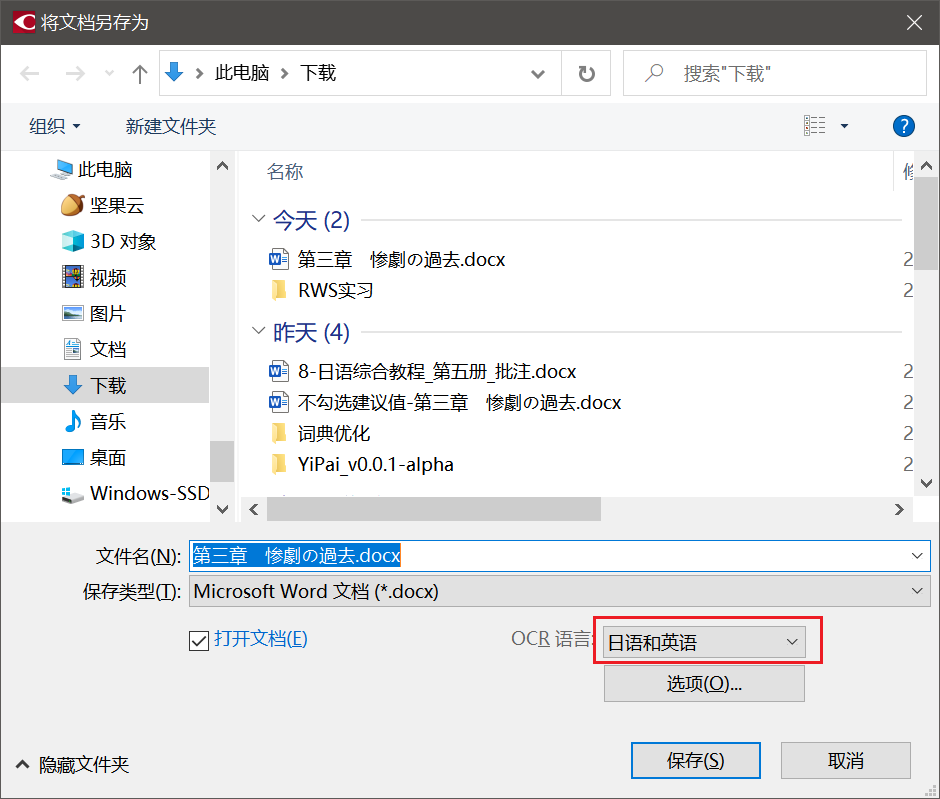
### 选择语言
如果上一步找不到`日语`,那么选择`更多语言`

拉动滚动条,找到`日语`勾上就可以了

## 识别模式
设置好语言后,点击`选项`

在`格式设置`里的`文档布局`里选择`精确副本`——这就意味着得到一个与 PDF 完全一样的竖排文档
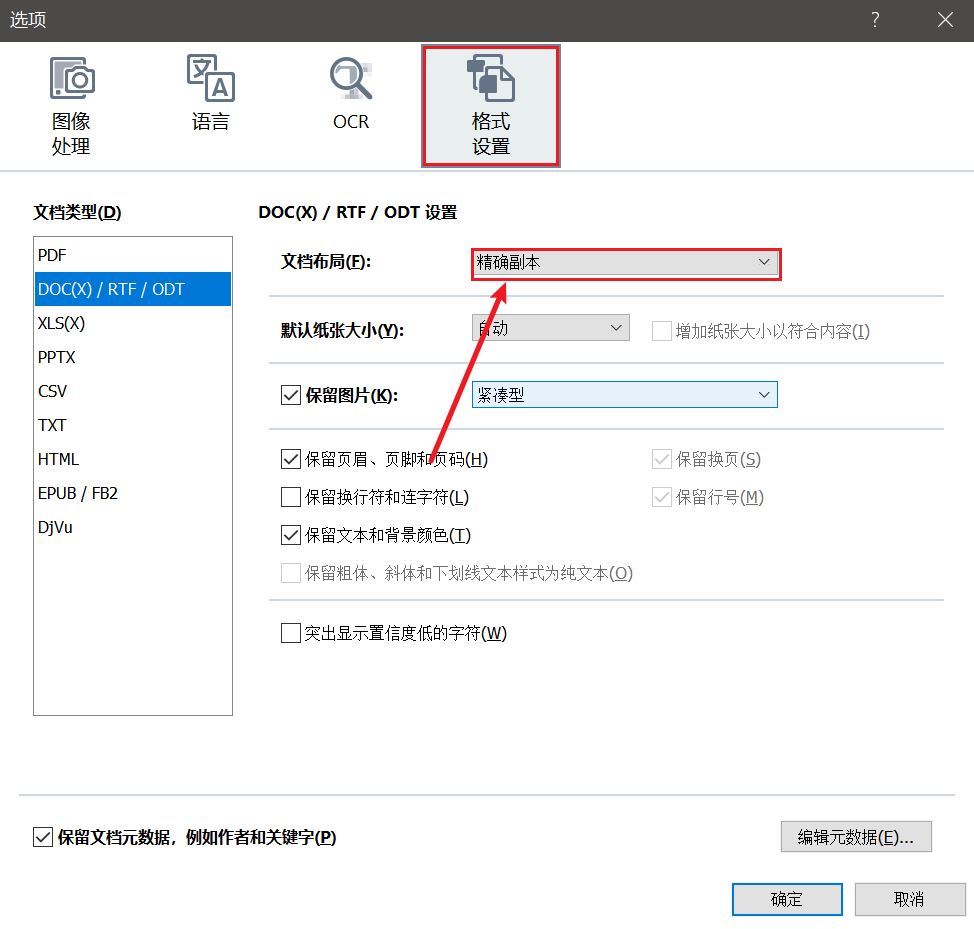
也可以选择`格式化文本`——这样就可以得到一个符合中文排版习惯的文档

选择完后,点击确定,然后就会回到下面这个弹窗,点击`保存`即可

转换过程可能会花一点时间,耐心等待即可。
最后,给一个生成的最终效果:
`精确副本`

`格式化文本`

当然生成的 Word 为了保持和 PDF 一样的页面排版,会夹杂着各种分页符、换行符,而且很多同学最终是要用下面这样排版交作业的,这个时候还得一页一页地手动粘贴过去……
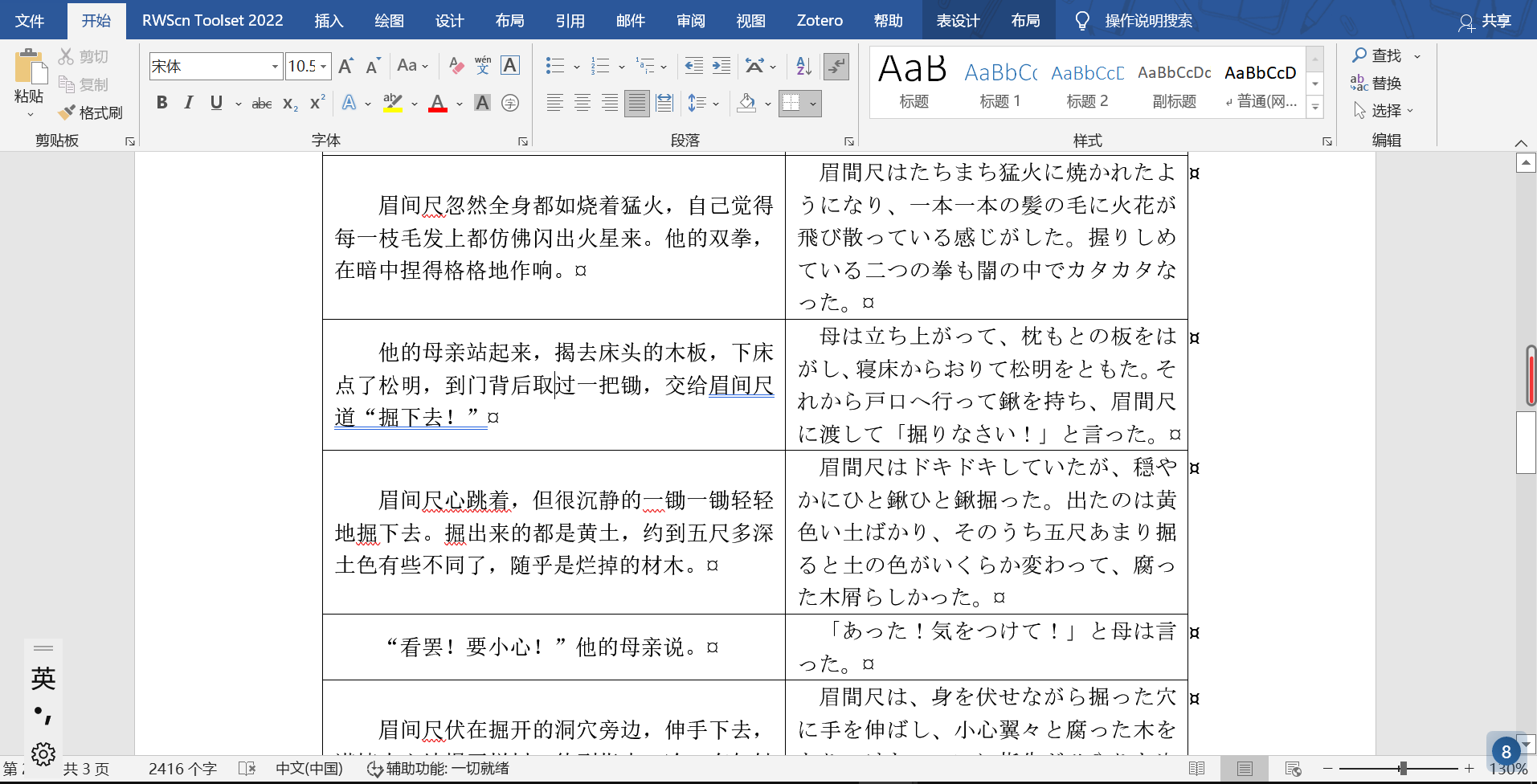
这个时候,就推荐本人开发的一个小工具[译排](https://gitee.com/NoHeartPen/yipai)啦(~~好像暴露了我写这篇文章的目的~~),感兴趣的话,可以戳[「YiPai」·「译排」 · 语雀 (yuque.com)](https://www.yuque.com/noheartpen/tnxvz0/rdi750)了解更多
# 转换为 PDF
可能有人会注意到,ABBYY 有一个可以转成`可搜索的 PDF`的选项

估计很多用 iPad 的同学会有点兴趣,所以就简单介绍一下——操作上和上面转成 Word 是一样的。
这个选项生成的 PDF 就是把识别出的文字嵌到了 PDF 的对应位置——但不会影响原来的图像
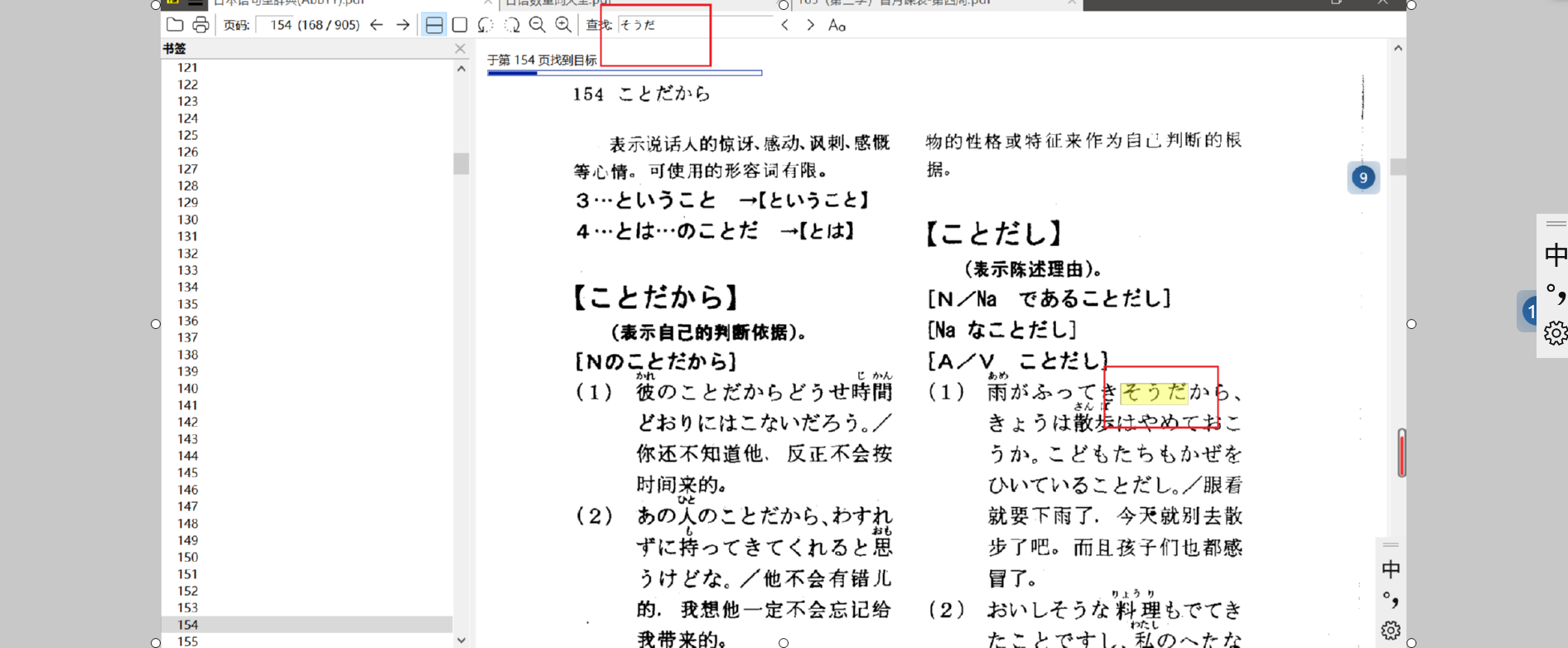
而 WPS、浏览器等都是支持搜索功能的,这不就相当于一本电子词典么?
强烈,建议在淘宝付费购买的 PDF 都这样处理一下,就可以像下面一样快速查词:
# 在 OCR 编辑器中打开
很多同学其实一般是不会把 PDF 转成 Word 的,因为或多或少都有错别字,排版也不是很好,需要花时间校对。估计也就在要交给老师的时候,才会用这个。
这种情况下,要确认 Word 中可能识别错了的地方,就得浪费不少时间找 PDF 中的相应位置。
所以,如果对识别的准确度有较高要求的话,在右键选择转换方式的时候,最好选择「在 OCR 编辑器打开」的选项

点击上面的提到的`在 OCR 编辑器打开`,就会进到下面这个界面
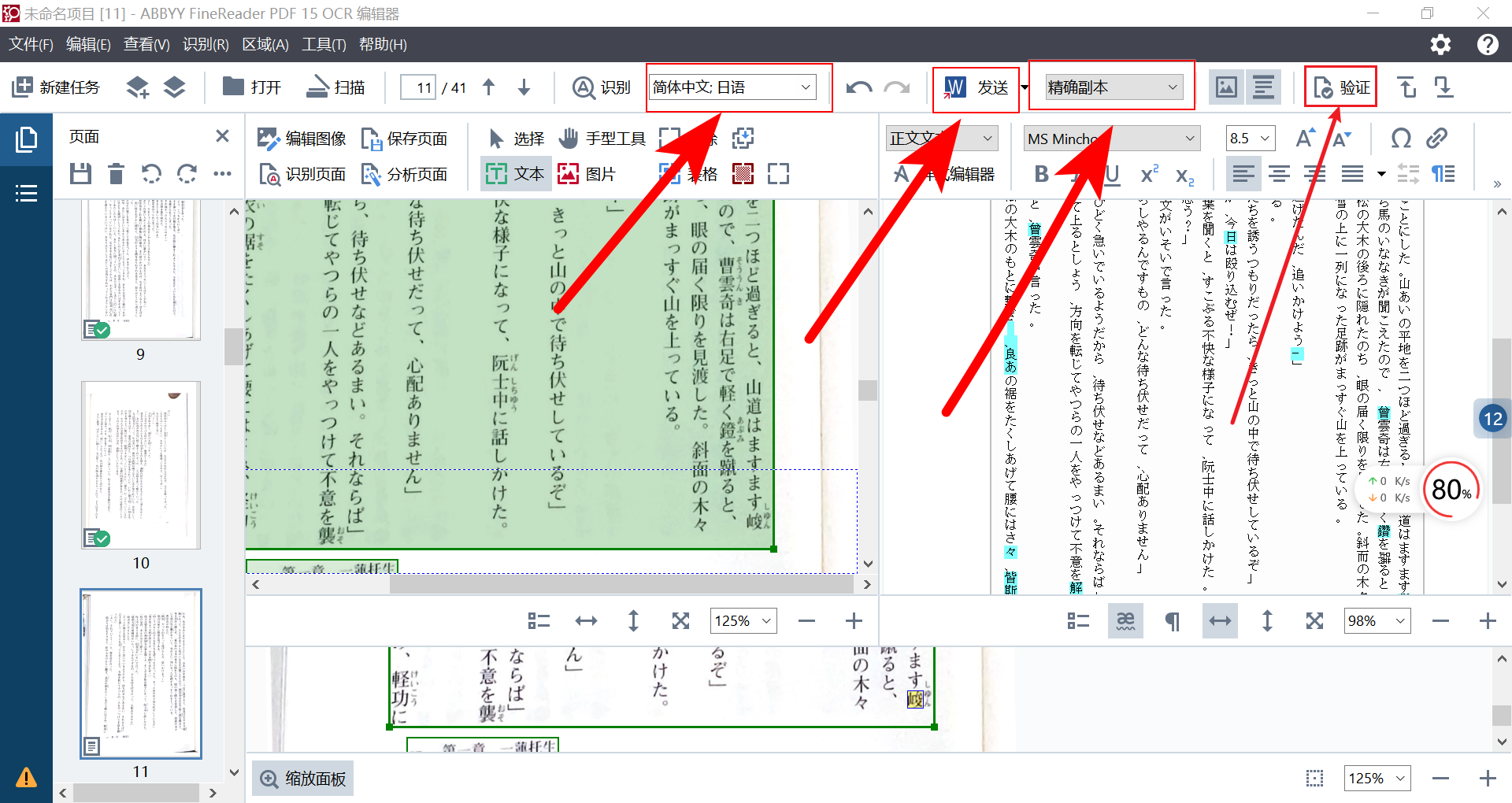
看着挺复杂的,但其实大多数人只会用到我箭头指的四个地方——前三个和前面介绍的一样,第四个`验证`(也就是箭头最细的那个)没有介绍过,但用起来也很简单。
点击`验证`,就可以得到下面的界面
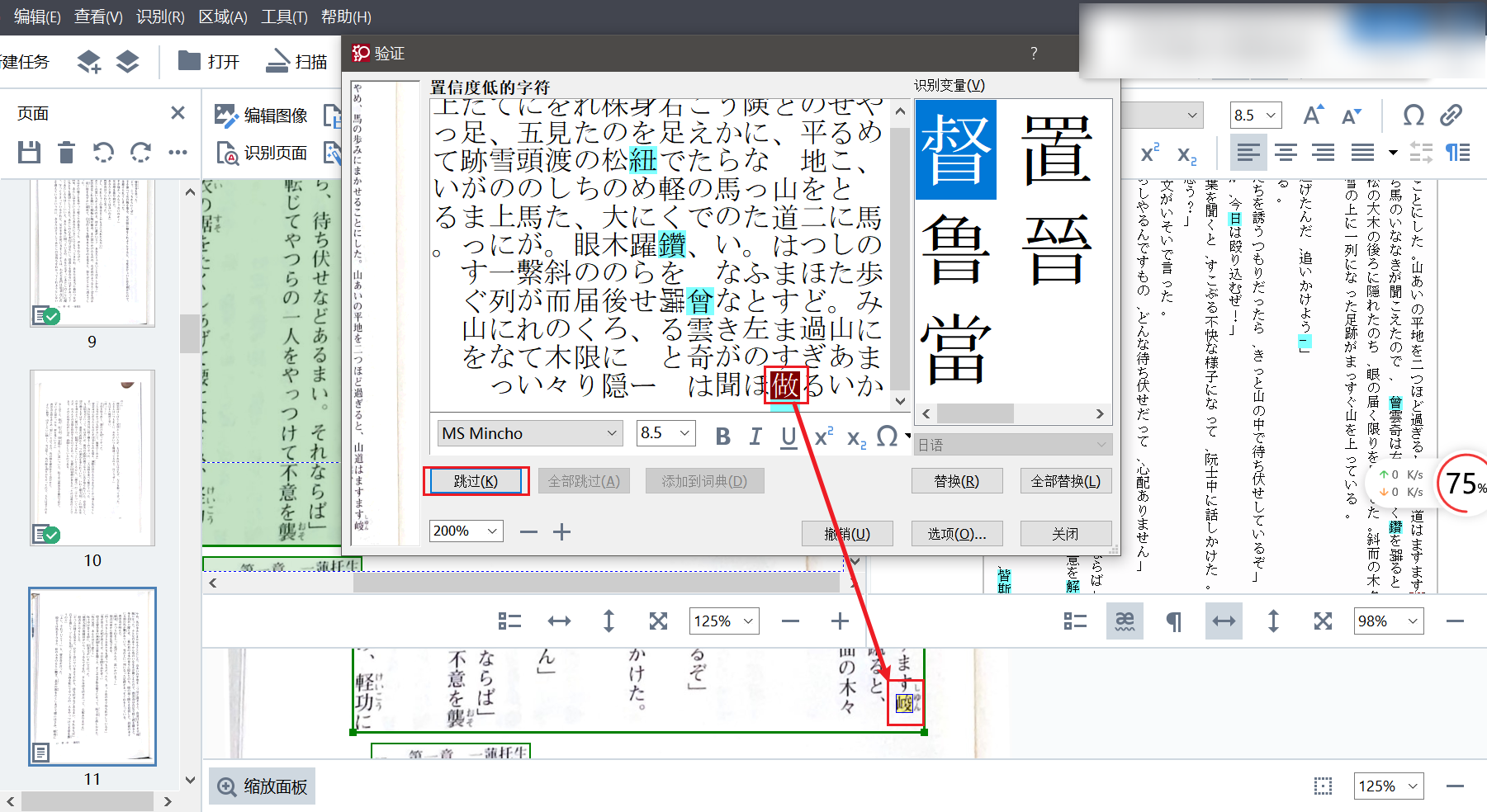
ABBYY 会在这里提示它有可能识别错了的地方,并且会同时高亮 2 个地方,把光标移到上面就直接打字修改就可以了。

修改完一个之后点击`跳过`,就会移动到下一个有可能存在错误的地方。当然如果是 ABBYY 误报的话,直接点击`跳过`就可以了。
全部修改完后,点击`关闭`,
然后点击`精确文本`(其他也行)选择导出的文档布局,最后选择`发送`就可以了。

# 对比文档
有人可能好奇,红框框起的的软件功能是什么(~~好吧……其实是我懒得写其他几个了~~)

这个功能也可以用来校对,把 PDF 放左边,把 ABBYY 导出的 Word 放右边,然后选择`文档语言`——尴尬的是没有日语……

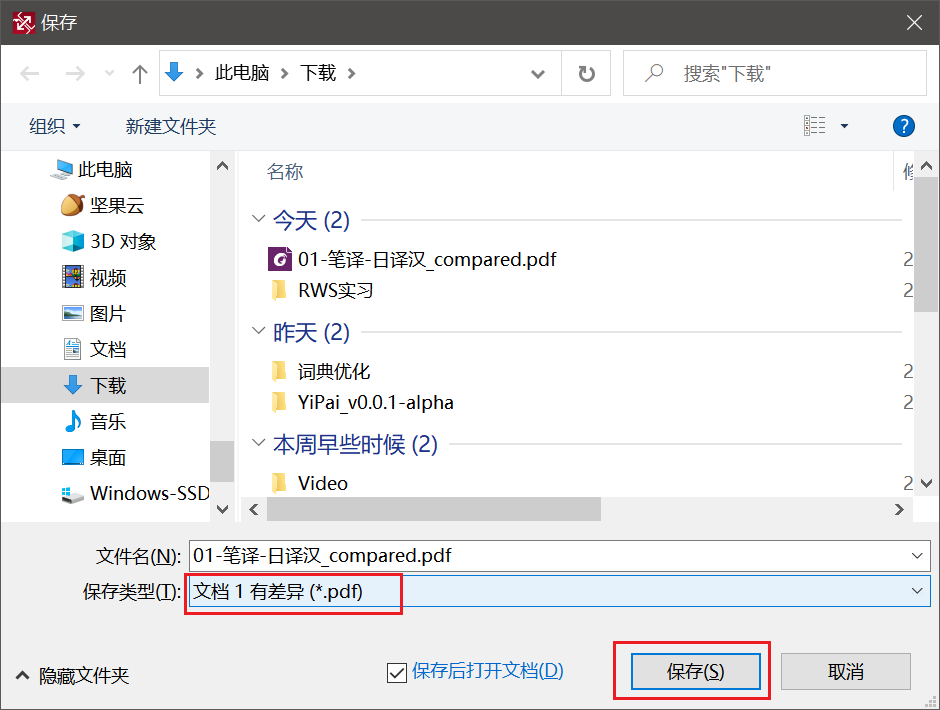
如果用`简体中文`来对比,那么对比之后,点击`保存`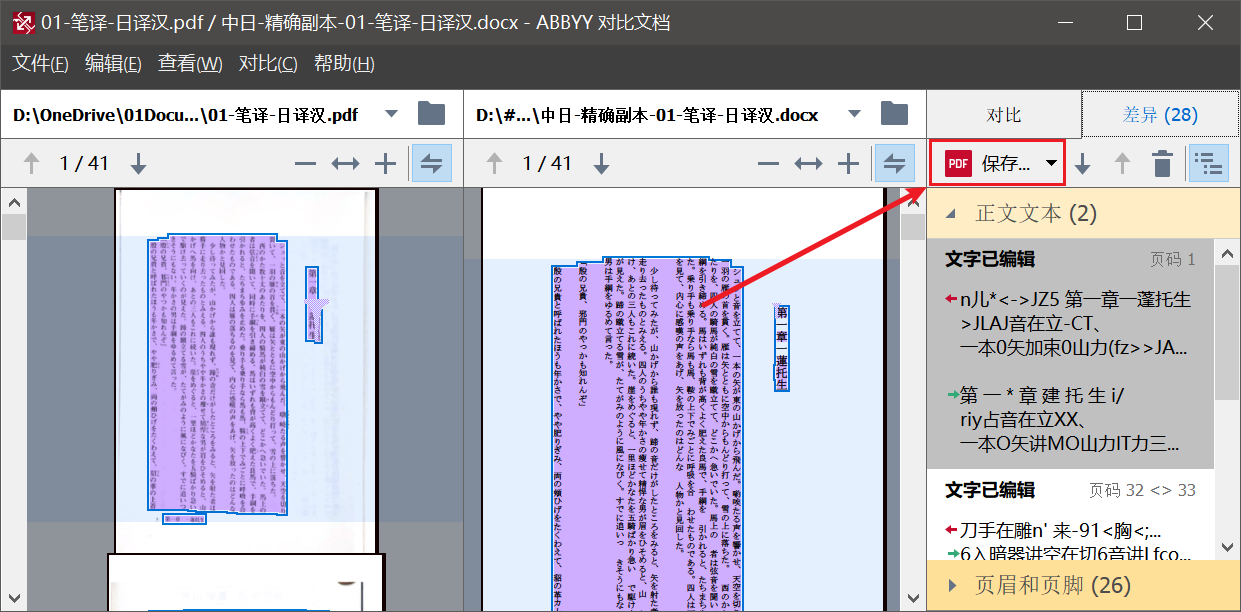
选择第一个就好

然后就选择保存位置(这里也可以改上一步的设置)
然后比对 PDF 中高亮部分就可以了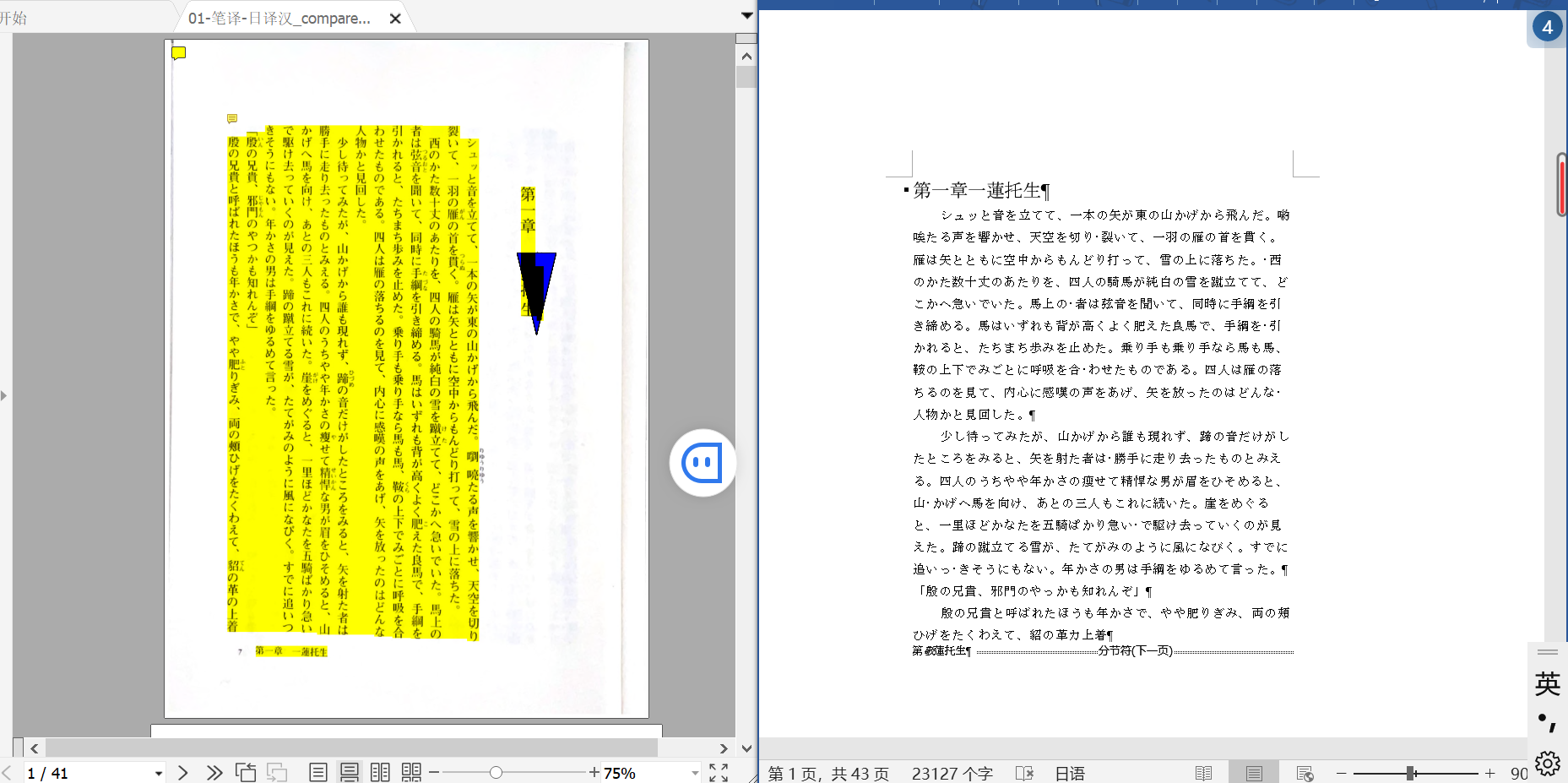
但由于这个功能本身不支持日语,所以左边的 PDF 的文本都被高亮——这还不如不高亮呢……
所以这个功能只能用来快速校对中文的 PDF 和 Word
至于日语,还是用`在 OCR 编辑器中打开`的`验证`一个一个地校对吧。
# 补充
- 转换模式的区别:随便找个文件挨个试试就明白了……
## 如何转成 Kindle 等墨水屏也能看的 PDF/如何处理拍得稀烂的 PDF
在选项的`图像处理`的`显示自定义设置`里面改吧
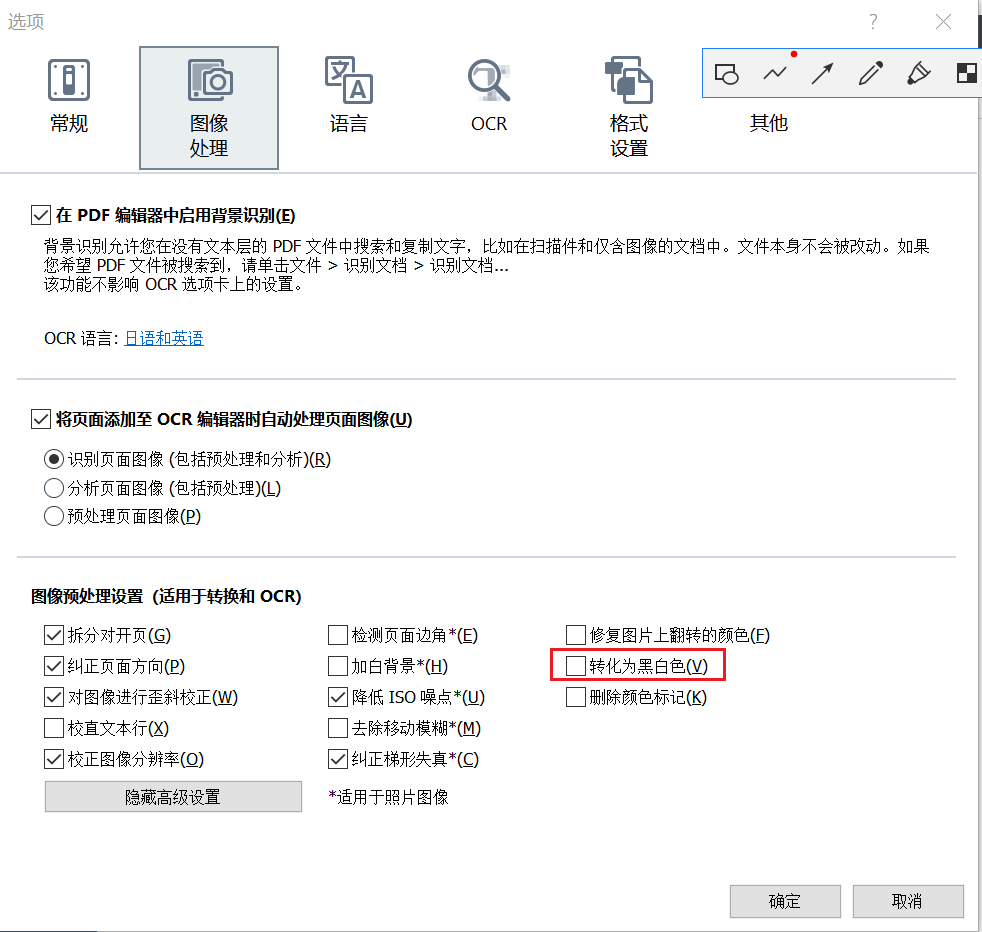
如果只是为了让墨水屏显示得更清晰,勾选`转换为黑白色`就可以了,其他的选项我也没折腾过
## 如何解决对开页的问题
像这种双页的 PDF 不仅在小屏幕上看着不方便(有 iPad 的请随意……),还(可能)会导致识别效果下降

所以如何切成下面这种单页的 PDF 就是个技术活了——非常麻烦,我一般只在有必要时才搞

个人推荐用[福昕高级 PDF 编辑器](https://www.foxitsoftware.cn/downloads/),它们的`裁剪页面`和`提取`很好用

用其他的也行,我用福昕高级 PDF 编辑器只是因为随时预览效果,避免漏裁(但福昕 PDF 阅读器好像没有这个功能)
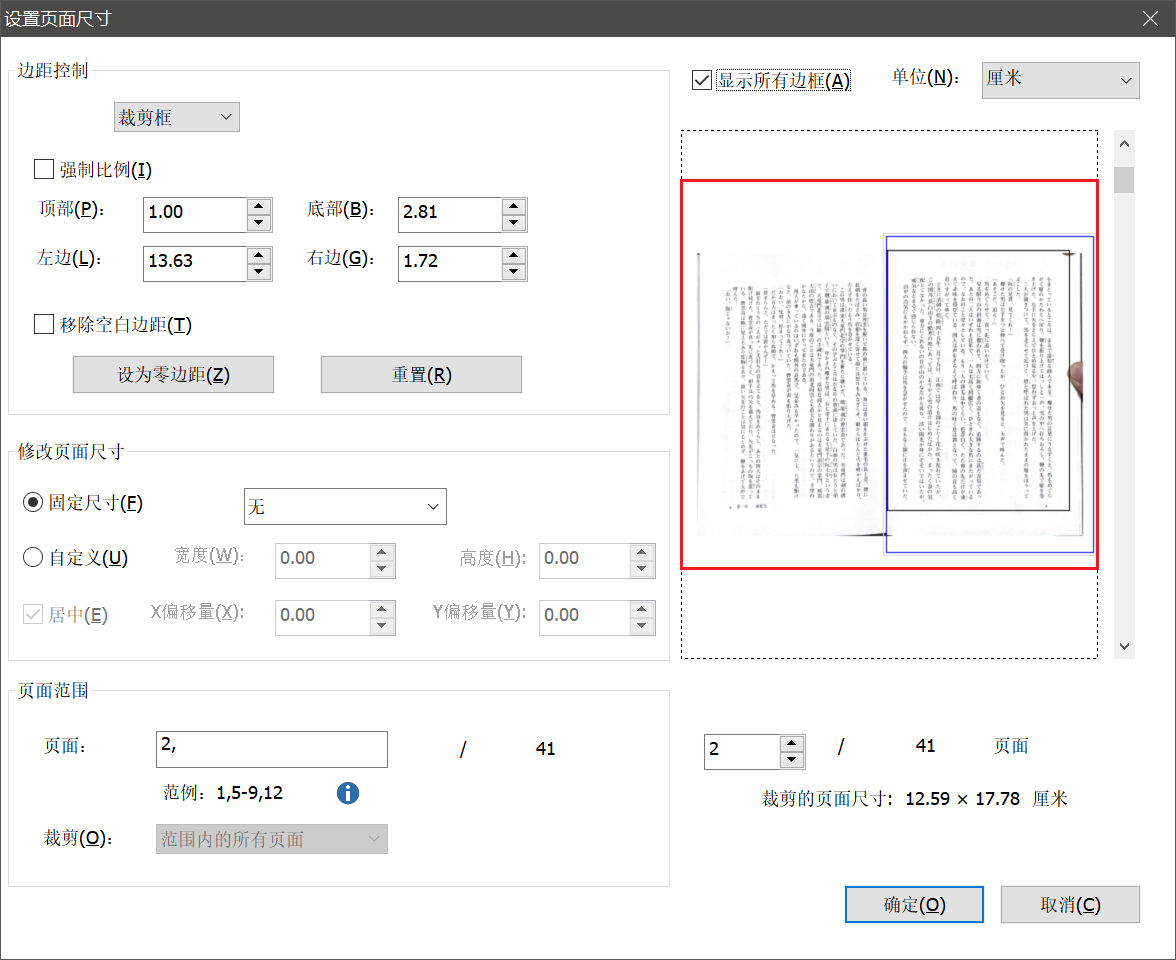
把所有单数页都转成 PNG 到一个文件夹,再把所有偶数页转到一个文件夹
之后,再用 2345 好压的批量文件改名,修改成`55-源文件名`这样的风格(这样在合成时页码才不会乱)

注意批量修改时可以注意下这三个地方
# 参考
[有没有可以识别日文的 OCR 软件? - 知乎 (zhihu.com)](https://www.zhihu.com/question/320456344/answer/2613044602):基于本文的一个备份
[SourceBook——使用GAN提高扫描书籍分辨率](https://forum.freemdict.com/t/topic/21752):对设备的性能要求比较高。
[【OCR 进阶系列教程分享】 ](https://www.bilibili.com/video/BV1ga4y1s73w?p=2&share_source=copy_web&vd_source=c968117e55645b439b5c5d2865ff0caa):一个很详细的视频教程,但不是针对日语进行讲解
[OCR 文字识别软件 · 语雀 (yuque.com)](https://www.yuque.com/docs/share/177c6f55-dfff-4fd5-8d71-7374c7128a5e):推荐了其他大量的 OCR 软件,并且附带软件下载资源
[秒杀年费 258 的同款 APP,微软、联想、Adobe、腾讯的良心产品太香了! (qq.com)](https://mp.weixin.qq.com/s?__biz=MzA5NjEwNjE0OQ==&mid=2247504889&idx=1&sn=eac708f80285cf7eb630fb9c9b1c4fa2&chksm=90b7b033a7c03925574cd74b646e0e30a2787abe72928919a55577b1676ee586ca4504a823a0&scene=4):手机端的 OCR 软件测评
有能力的的话可以支持下官方正版:[购买 OCR 文字识别软件,ABBYY FineReader PDF](https://www.abbyychina.com/buy.html)