#software #ai #llm #open-source
[[🦙 Understanding LLaMA2 Part 1 Model Architecture]]
[[🦙 Understanding LLaMA2 Part 2 KV Cache]]
[[🦙 Understanding LLaMA2 Part 3 PyTorch Implementation]]
[[🦙 Understanding LLaMA2 Part 4 ExecuTorch Runtime]]
[[🦙 Understanding LLaMA2 Part 5 Training with TinyStories]]
> I was involved in the early ExecuTorch definition phase and had used its predecessor Lite Interpreter extensively in work. I really like this idea and its design. This is a great effort among multiple industry leading companies. So I'm trying the open-source version with LLaMA2.
# [ExecuTorch Overview](https://pytorch.org/executorch-overview)
## What is ExecuTorch?
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are:
- **Portability**: Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers.
- **Productivity**: Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms.
- **Performance**: Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs and DSPs.
## Why ExecuTorch?
Supporting on-device AI presents unique challenges with diverse hardware, critical power requirements, low/no internet connectivity, and realtime processing needs. These constraints have historically prevented or slowed down the creation of scalable and performant on-device AI solutions. We designed ExecuTorch, backed by our industry leaders like Meta, Arm, Apple, and Qualcomm, to be highly portable and provide superior developer productivity without losing on performance.
## Setup ExecuTorch
Follow https://pytorch.org/executorch/stable/getting-started-setup.html to setup ExecuTorch
# Compile with ExecuTorch
> We continue to use the same github repo at https://github.com/jimwang99/understanding-llama2/tree/main/pytorch
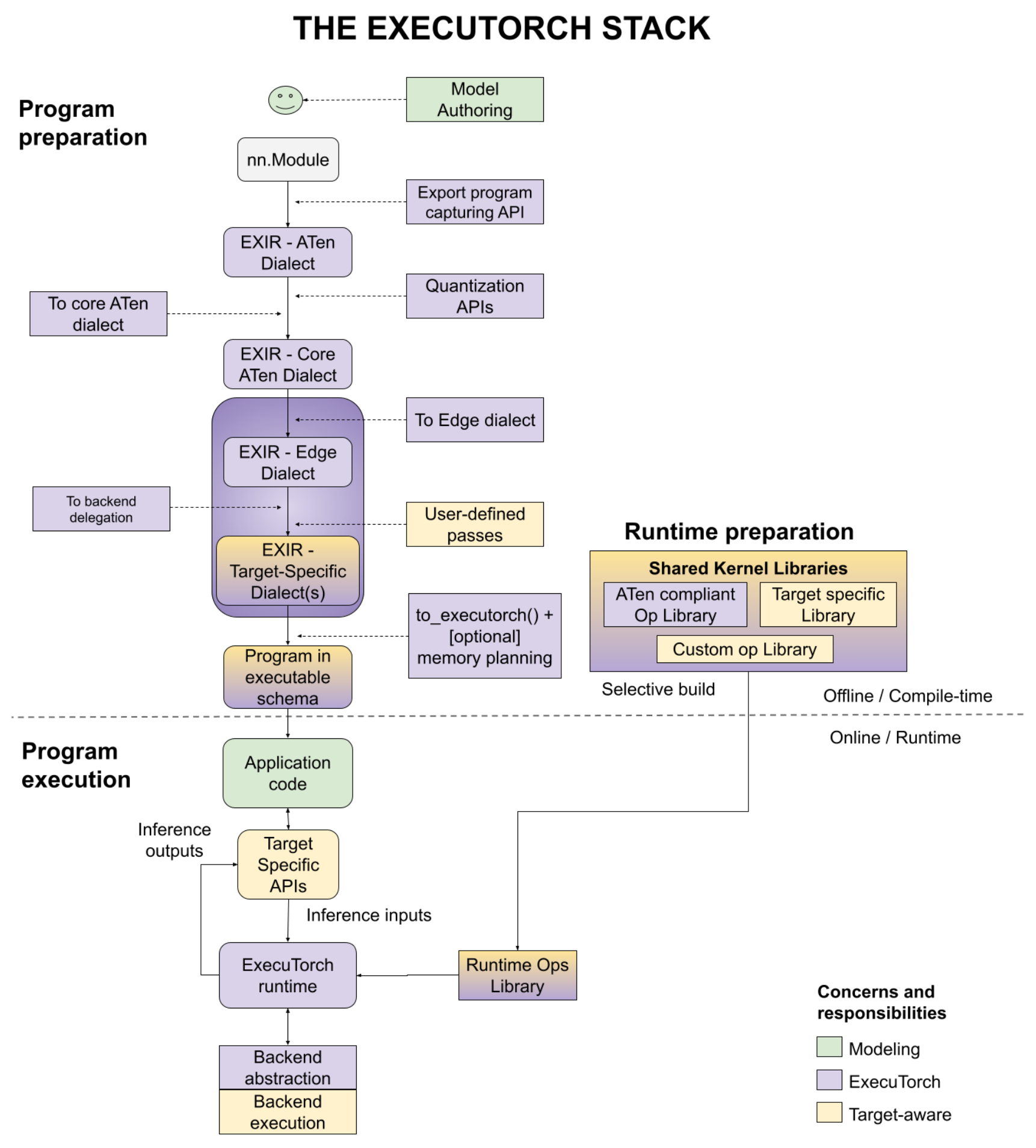
To achieve smaller binary size and higher execution efficiency, there are some limitations imposed on models, such as dynamism and sometimes its formality. So I'm copying the original `model.py` to `executorch.py`, so that we can modify the model and compile it in ExecuTorch.
Some minor modifications in eager mode
1. Comment out `_trace_and_check()`
2. Comment out logger
## Dynamism
Dynamism is the key for optimize runtime efficiency. ExecuTorch chooses to trade-off certain level of dynamism for better runtime efficiency.
### Branches
One important method it uses is to trace the model at compile time, and eliminate branches that is not necessary, while keeping essential ones. At this moment it supports `if ... else ...` and `for` loops with constant range.
### Dynamic shapes
In LLM, one important dynamism is the length of its input tokens, `L`, which depends on the input prompt and how many tokens have been previously generated. In ExecuTorch, we need to define the upper bound of `L` so that ExecuTorch runtime knows how much memory needs to be allocated for related tensors.
...
### Dynamic slicing
Because of dynamic input length, `L`, we need to slice `cos`, `sin` and `mask` accordingly. **This kind of dynamism is not supported by ExecuTorch, at least as of today (Nov. 2023)**. Our solution is to move this part of code, slicing, out of the model into a `preproc` step.
# Run with ExecuTorch
## Python runtime
## C++ runtime
#TODO